Chaos Engineering ── 本番で障害を「わざと」起こす
扱うCS概念:障害注入(Fault Injection)、Blast Radius の制御、定常状態仮説、Gameday、Steady-State Hypothesis
この章で何ができるようになるか:「本番環境で意図的に障害を起こす」ことがなぜ信頼性向上につながるのかを説明できるようになる。Chaos Engineering の原則と、安全に実施するためのフレームワークを理解できる。
問題設定
「テスト環境では動いたのに、本番で障害が起きた」──なぜか。
テスト環境と本番の違い:
- トラフィック量が100倍〜1000倍
- AZ(アベイラビリティゾーン)が複数にまたがる
- 依存サービスが実際に落ちる(テスト環境ではモック)
- ネットワークの遅延・パケットロスが発生する
- GC Pause、ディスクフル、DNS障害が起きる
本番でしか起きない障害の例:
- AZ-a が落ちたとき、フェイルオーバーが実は機能しない
- 依存サービスが遅くなったとき、タイムアウトが設定されておらず全体が止まる
- キャッシュが全消えしたとき、DB が過負荷で落ちる
- 証明書の期限が切れたとき、自動更新が動かないChaos Engineering の原則
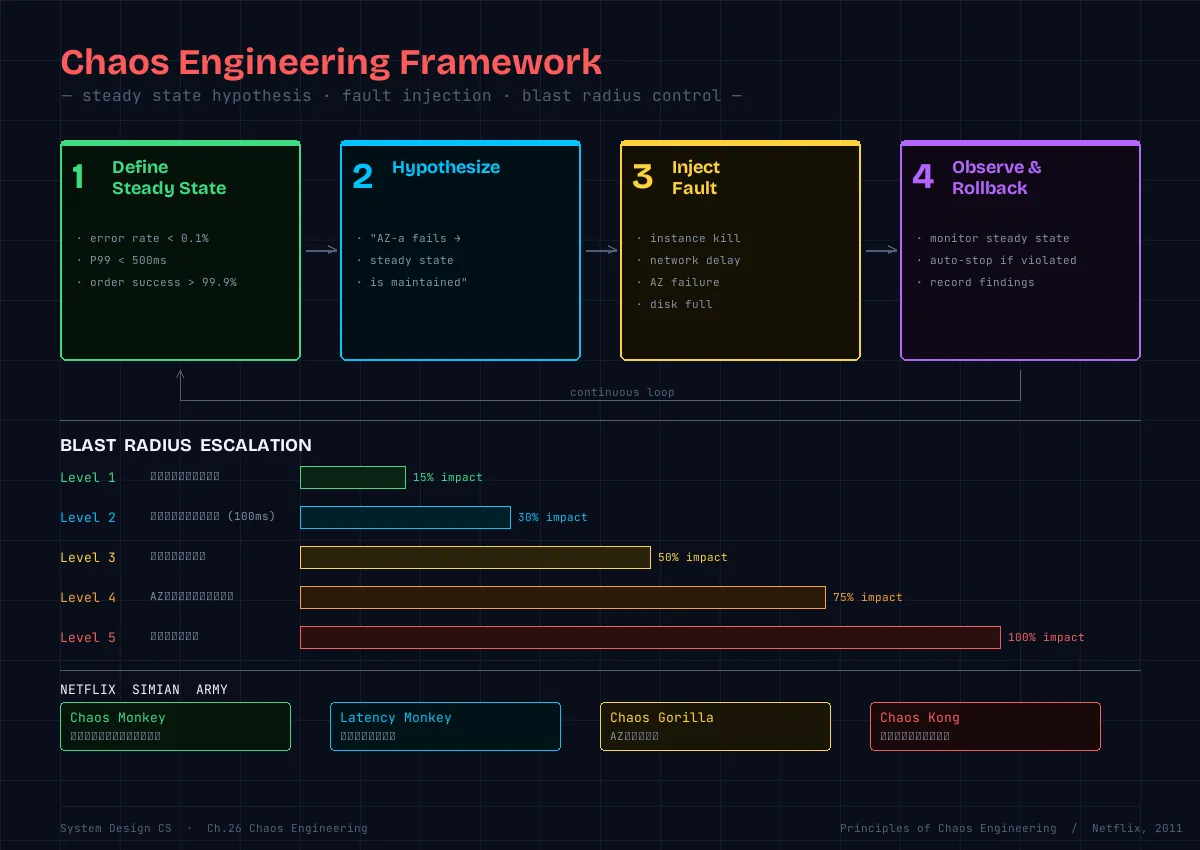
Netflix は 2010年頃から Chaos Monkey を開発し、2011年に Simian Army として公開した。その知見をもとに、2015年に “Principles of Chaos Engineering” が体系化された(principlesofchaos.org)。
1. 定常状態(Steady State)を定義する
→ 「正常とは何か」を数値で定義する
→ 例:エラー率 < 0.1%、P99 レイテンシ < 500ms、注文成功率 > 99.9%
2. 仮説を立てる
→ 「AZ-a が落ちても、定常状態は維持される」
→ 「Redis が落ちても、DB へのフォールバックで定常状態は維持される」
3. 本番(に近い環境)で実験する
→ 本番トラフィックでないと再現しない問題がある
→ Blast Radius を制御して安全に実施
4. 実験を自動化して継続的に実行する
→ 一度やって終わりではない。システムは変化し続けるNetflix の Simian Army
Netflix が開発した Chaos Engineering ツール群。
Chaos Monkey:ランダムに本番インスタンスを終了させる
→ 単一インスタンス障害に対する耐性を検証
→ 毎日自動実行
Chaos Gorilla:AZ 全体をシミュレーション障害させる
→ AZ障害時のフェイルオーバーを検証
Latency Monkey:サービス間通信に人為的な遅延を注入
→ タイムアウト設定とサーキットブレーカーの検証
Chaos Kong:リージョン全体の障害をシミュレート
→ リージョン間フェイルオーバーの検証(最も大規模)障害注入の実装パターン
パターン1:インスタンス終了
import boto3
import random
class ChaosMonkey:
def __init__(self, asg_name: str, dry_run: bool = True):
self.ec2 = boto3.client('ec2')
self.asg = boto3.client('autoscaling')
self.asg_name = asg_name
self.dry_run = dry_run
def terminate_random_instance(self):
"""Auto Scaling Group 内のランダムなインスタンスを終了"""
response = self.asg.describe_auto_scaling_groups(
AutoScalingGroupNames=[self.asg_name]
)
instances = response['AutoScalingGroups'][0]['Instances']
healthy = [i for i in instances if i['HealthStatus'] == 'Healthy']
if len(healthy) <= 1:
print("Only 1 healthy instance. Skipping.")
return
target = random.choice(healthy)
instance_id = target['InstanceId']
if self.dry_run:
print(f"[DRY RUN] Would terminate {instance_id}")
else:
self.ec2.terminate_instances(InstanceIds=[instance_id])
print(f"Terminated {instance_id}")パターン2:ネットワーク障害注入(tc コマンド)
# 100ms の遅延を追加
tc qdisc add dev eth0 root netem delay 100ms 20ms
# 5% のパケットロス
tc qdisc add dev eth0 root netem loss 5%
# 帯域制限(1Mbps)
tc qdisc add dev eth0 root tbf rate 1mbit burst 32kbit latency 400ms
# 元に戻す
tc qdisc del dev eth0 rootパターン3:アプリケーションレベルの障害注入
# Feature Flag + Chaos Middleware
class ChaosMiddleware:
"""リクエストの一部に人為的な障害を注入"""
def __init__(self, config: dict):
self.config = config
# config = {
# "enabled": True,
# "latency_ms": 500, # 追加レイテンシ
# "error_rate": 0.05, # 5% エラー率
# "target_paths": ["/api/orders"],
# "target_percentage": 1, # 対象リクエストの1%
# }
async def __call__(self, request, call_next):
if not self._should_inject(request):
return await call_next(request)
# レイテンシ注入
if self.config.get("latency_ms"):
await asyncio.sleep(self.config["latency_ms"] / 1000)
# エラー注入
if random.random() < self.config.get("error_rate", 0):
return JSONResponse(
status_code=503,
content={"error": "chaos: simulated failure"},
headers={"X-Chaos-Injected": "true"}
)
return await call_next(request)
def _should_inject(self, request) -> bool:
if not self.config.get("enabled"):
return False
if request.url.path not in self.config.get("target_paths", []):
return False
return random.random() * 100 < self.config.get("target_percentage", 0)Blast Radius の制御
「本番で障害を起こす」ことの最大のリスクは、実験が手に負えなくなること。
Blast Radius を制御する原則:
1. 段階的に拡大する
開発環境 → ステージング → 本番の1% → 本番の10% → 本番全体
2. 自動停止条件を設定する
定常状態の指標が閾値を超えたら即座に実験を中止
3. 最初は最も影響の小さい実験から
インスタンス終了 → ネットワーク遅延 → AZ 障害 → リージョン障害
4. 営業時間内に実施する
障害対応できるチームが待機しているタイミングでclass ChaosExperiment:
"""安全に Chaos 実験を実行するフレームワーク"""
def __init__(self, name: str, steady_state_check, injection_fn, rollback_fn):
self.name = name
self.check_steady_state = steady_state_check
self.inject = injection_fn
self.rollback = rollback_fn
async def run(self):
print(f"[CHAOS] Starting experiment: {self.name}")
# 1. 実験前:定常状態を確認
if not await self.check_steady_state():
print("[CHAOS] System not in steady state. Aborting.")
return {"status": "aborted", "reason": "pre-check failed"}
# 2. 障害注入
print("[CHAOS] Injecting fault...")
await self.inject()
# 3. 定常状態を監視(30秒間)
for i in range(6):
await asyncio.sleep(5)
if not await self.check_steady_state():
print(f"[CHAOS] Steady state violated at {(i+1)*5}s. Rolling back!")
await self.rollback()
return {"status": "failed", "violation_at_seconds": (i+1)*5}
# 4. 実験成功 → ロールバック
await self.rollback()
print(f"[CHAOS] Experiment passed: {self.name}")
return {"status": "passed"}
# 使用例
experiment = ChaosExperiment(
name="Redis failure resilience",
steady_state_check=lambda: check_error_rate() < 0.01,
injection_fn=lambda: kill_redis_primary(),
rollback_fn=lambda: restart_redis_primary(),
)
result = await experiment.run()Gameday:組織的な障害訓練
Chaos Engineering は技術だけでなく、組織的な障害対応力を鍛える側面もある。
Gameday の流れ:
1. シナリオ設計(1週間前)
→ 「決済サービスが30分間応答しなくなった」
→ 影響範囲の事前評価、安全対策の確認
2. 事前アナウンス
→ 関係チームに実施日時を通知
→ オンコール体制を確認
3. 実施(当日)
→ ファシリテーターが障害を注入
→ オンコールチームが「通常の障害対応フロー」で対応
→ 観察者がタイムラインを記録
4. 振り返り(Post-mortem)
→ アラートは適切に発火したか?
→ ランブック通りに対応できたか?
→ 自動復旧は機能したか?
→ 改善アクションの洗い出しChaos Engineering を始める際のチェックリスト
前提条件(これがないと Chaos Engineering は危険):
□ 基本的な監視・アラートが整備されている
□ オンコール体制が機能している
□ ロールバック手段が確立されている
□ Auto Scaling / 自動復旧が設定されている
最初に試すべき実験(影響が小さい順):
1. 単一インスタンスの終了
2. 依存サービスへの遅延注入(100ms)
3. キャッシュ(Redis)の障害
4. DB Read レプリカの障害
5. AZ 障害のシミュレーションまとめ
| 原則 | 実践 | ツール例 |
|---|---|---|
| 定常状態の定義 | SLI/SLO を数値化 | Prometheus + Grafana |
| 仮説の設定 | 「Xが起きても定常状態を維持」 | 実験計画書 |
| 障害注入 | インスタンス終了・遅延・エラー | Chaos Monkey, Litmus, tc |
| Blast Radius 制御 | 段階的拡大 + 自動停止 | Feature Flag + 監視 |
| 自動化 | CI/CD パイプラインに組み込み | Chaos Mesh (K8s) |
| 組織訓練 | Gameday(定期的な障害訓練) | 振り返り・ランブック更新 |
Chaos Engineering の本質は「障害を恐れるのではなく、障害に慣れる」ことだ。障害は必ず起きる。問題は「起きたとき、システムと組織がどう振る舞うか」を事前に確認しておくことにある。