不正検知 & レコメンデーション ── グラフで「つながり」を武器にする
扱うCS概念:グラフ異常検知、PageRank、協調フィルタリング、行列分解、GraphSAGE(グラフニューラルネットワーク)
この章で何ができるようになるか:グラフ構造が「孤立したデータ点」では見えないパターンを可視化することを理解できる。不正検知とレコメンデーションという一見異なる問題が、どちらも「グラフ上の伝播・影響力」として統一的に解けることを説明できる。
問題設定:2つの応用
不正検知(PayPal/Stripe)
シナリオ:
- アカウントAが新規作成された
- Aが過去に不正と判定されたアカウントB、Cと同じIPアドレスを使ったことがある
- BはデバイスフィンガープリントがDと一致する
- DはすでにBANされたアカウントEとメールドメインが同じ
Aを「怪しい」と判断できるか?
→ 属性情報(IPアドレス・デバイス)だけでは「ルールベース」の限界。
グラフ上の「近さ」で判定する。レコメンデーション(Netflix/Amazon)
シナリオ:
- ユーザーXは映画A、B、Cを高評価した
- ユーザーYも映画A、Bを高評価し、さらに映画Dも高評価している
- → XにDを推薦するべきでは?(協調フィルタリング)
→ ユーザーとコンテンツを「二部グラフ(Bipartite Graph)」として表現することで、
「似ているユーザー」「似ているコンテンツ」が自然に求まる。不正検知:グラフ上の汚染伝播
エンティティグラフの構築
graph LR
A[アカウントA<br/>新規] ---|同じIP| IP1[IP: 192.168.1.1]
B[アカウントB<br/>不正確定] ---|同じIP| IP1
B ---|同じデバイス| Device1[デバイス: abc123]
C[アカウントC<br/>不正確定] ---|同じデバイス| Device1
C ---|同じメールドメイン| Domain1[ドメイン: tempmail.com]
D[アカウントD<br/>BAN済み] ---|同じメールドメイン| Domain1
style A fill:#ffeb3b
style B fill:#f44336
style C fill:#f44336
style D fill:#f44336このグラフ上で、アカウントAは2ホップ以内に3つの不正アカウントと接続されている。
ラベル伝播アルゴリズム(Label Propagation)
def label_propagation(graph: dict, seeds: dict[str, float],
iterations: int = 10, damping: float = 0.8) -> dict[str, float]:
"""
seeds: {ノードID: 初期不正スコア}(確定済み不正アカウントは1.0)
返り値: {ノードID: 不正スコア(0.0〜1.0)}
"""
scores = {node: seeds.get(node, 0.0) for node in graph}
for _ in range(iterations):
new_scores = {}
for node in graph:
if node in seeds:
# 確定済みノードのスコアは変えない
new_scores[node] = seeds[node]
continue
neighbors = graph.get(node, [])
if not neighbors:
new_scores[node] = scores[node]
continue
# 隣接ノードのスコアの平均値を伝播
neighbor_avg = sum(scores[n] for n in neighbors) / len(neighbors)
# damping: 伝播の減衰(遠くなるほど影響が小さくなる)
new_scores[node] = damping * neighbor_avg + (1 - damping) * scores[node]
scores = new_scores
return scores
# 使用例
fraud_graph = {
"A": ["IP1"],
"B": ["IP1", "Device1"],
"C": ["Device1", "Domain1"],
"D": ["Domain1"],
"IP1": ["A", "B"],
"Device1": ["B", "C"],
"Domain1": ["C", "D"],
}
confirmed_fraud = {"B": 1.0, "C": 1.0, "D": 1.0}
scores = label_propagation(fraud_graph, confirmed_fraud)
print(f"Account A fraud score: {scores['A']:.3f}")
# → 0.512 程度(50%以上の不正スコア → 要審査フラグ)Louvain法:不正コミュニティの自動検出
個々のアカウントの評価だけでなく、「不正グループ(コミュニティ)」を丸ごと検出することも重要だ。Louvain法はグラフのコミュニティ(密に接続されたクラスター)を自動的に見つける。
# python-louvain ライブラリ
import community as community_louvain
import networkx as nx
G = nx.Graph()
G.add_edges_from([
("A", "IP1"), ("B", "IP1"), ("B", "Device1"),
("C", "Device1"), ("C", "Domain1"), ("D", "Domain1")
])
# コミュニティ検出
partition = community_louvain.best_partition(G)
# → {"A": 0, "IP1": 0, "B": 0, "Device1": 0, "C": 1, "Domain1": 1, "D": 1}
# コミュニティ0(A, B, IP1, Device1)とコミュニティ1(C, D, Domain1)に分割
# コミュニティ0 に不正確定ノードが多ければ、A も同一グループとして審査PageRank:重要なノードを見つける汎用アルゴリズム
Google の検索ランキングで有名な PageRank だが、その応用は幅広い。
アイデア:「重要なノードからリンクされているノードは重要だ」という再帰的な定義。
def pagerank(graph: dict, damping: float = 0.85, iterations: int = 100) -> dict[str, float]:
"""
damping: ランダムサーファーモデル(85%の確率でリンクを辿り、15%でランダムジャンプ)
"""
nodes = list(graph.keys())
N = len(nodes)
rank = {node: 1.0 / N for node in nodes} # 初期値:均等分配
# 逆リンク(誰がこのノードを指しているか)を作成
in_links: dict[str, list] = {node: [] for node in nodes}
for node, edges in graph.items():
for target in edges:
in_links[target].append(node)
for _ in range(iterations):
new_rank = {}
for node in nodes:
# このノードを指している全ノードからのPageRankの流入
incoming = sum(
rank[src] / len(graph[src]) # src のPageRankをその出力リンク数で割る
for src in in_links[node]
if graph[src] # 出力リンクがある場合のみ
)
new_rank[node] = (1 - damping) / N + damping * incoming
rank = new_rank
return rank不正検知への応用:
# 不正ノードが高PageRankを持つノードに接続されているほど、疑わしい
fraud_influence_rank = pagerank(fraud_graph)
# IP1やDevice1が複数の不正アカウントから参照されている → 高ランク
# → 高ランクのエンティティ(共有IP/デバイス)に接続しているアカウントを優先審査レコメンデーション:二部グラフとしてのユーザー×コンテンツ
graph LR
subgraph ユーザー
U1[ユーザーX]
U2[ユーザーY]
U3[ユーザーZ]
end
subgraph コンテンツ
I1[映画A]
I2[映画B]
I3[映画C]
I4[映画D]
end
U1 ---|評価5| I1
U1 ---|評価4| I2
U1 ---|評価5| I3
U2 ---|評価5| I1
U2 ---|評価4| I2
U2 ---|評価3| I4
U3 ---|評価4| I3
U3 ---|評価5| I4協調フィルタリング(User-based CF)
「XとYは似ているユーザー → Yが評価した映画DをXに推薦」。
import numpy as np
from scipy.spatial.distance import cosine
def user_based_cf(ratings: dict[str, dict[str, float]], target_user: str,
top_n_items: int = 10) -> list[tuple[str, float]]:
"""
ratings: {user_id: {item_id: rating}}
"""
# 全アイテムの一覧
all_items = set(item for user_ratings in ratings.values() for item in user_ratings)
# ユーザーをベクトル化(未評価は0)
def to_vector(user_id):
return np.array([ratings[user_id].get(item, 0.0) for item in sorted(all_items)])
target_vec = to_vector(target_user)
# 類似ユーザーを求める(コサイン類似度)
similarities = {}
for user in ratings:
if user == target_user:
continue
vec = to_vector(user)
if np.any(vec) and np.any(target_vec):
sim = 1 - cosine(target_vec, vec) # 1 に近いほど似ている
similarities[user] = sim
# 類似ユーザーが評価していて、ターゲットが未評価のアイテムを推薦
target_rated = set(ratings[target_user].keys())
recommendations: dict[str, float] = {}
for user, sim in sorted(similarities.items(), key=lambda x: -x[1])[:20]:
for item, rating in ratings[user].items():
if item not in target_rated:
recommendations[item] = recommendations.get(item, 0) + sim * rating
return sorted(recommendations.items(), key=lambda x: -x[1])[:top_n_items]行列分解(Matrix Factorization):Netflix Prize の中核技術
協調フィルタリングの問題点:ユーザー数・アイテム数が増えると類似度計算のコストが爆発(O(N²))。
**行列分解(SVD/ALS)**は「ユーザーの好み」と「コンテンツの特徴」を低次元の潜在ベクトルで表現することで、これを解決する。Netflix Prize(2009年)の優勝チーム BellKor’s Pragmatic Chaos は、行列分解を含む100以上のモデルのアンサンブルで勝利したが、行列分解が最も重要な基盤技術であった。
# 直感的な説明
# ユーザー × アイテムの評価行列 R を、
# R ≈ U × V^T に分解する(U: ユーザー行列、V: アイテム行列)
#
# 例えば潜在次元数 k=2 とすると:
# ユーザーX = [アクション好き=0.8, ロマンス好き=0.2]
# ユーザーY = [アクション好き=0.7, ロマンス好き=0.3]
# 映画A(Die Hard)= [アクション要素=0.9, ロマンス要素=0.1]
# 映画D(ノート)= [アクション要素=0.1, ロマンス要素=0.9]
#
# XのDへの予測評価 = X・D = 0.8*0.1 + 0.2*0.9 = 0.26(低い → 推薦しない)
# YのDへの予測評価 = Y・D = 0.7*0.1 + 0.3*0.9 = 0.34(Xよりは高い)
import torch
import torch.nn as nn
class MatrixFactorization(nn.Module):
def __init__(self, n_users: int, n_items: int, n_factors: int = 50):
super().__init__()
self.user_factors = nn.Embedding(n_users, n_factors)
self.item_factors = nn.Embedding(n_items, n_factors)
# バイアス項:各ユーザーの評価傾向、各アイテムの人気
self.user_biases = nn.Embedding(n_users, 1)
self.item_biases = nn.Embedding(n_items, 1)
def forward(self, user_ids: torch.Tensor, item_ids: torch.Tensor) -> torch.Tensor:
u = self.user_factors(user_ids)
v = self.item_factors(item_ids)
# 内積 + バイアス
dot = (u * v).sum(dim=1)
bias = self.user_biases(user_ids).squeeze() + self.item_biases(item_ids).squeeze()
return dot + biasGraphSAGE:グラフニューラルネットワークによる統合
2017年の GraphSAGE 論文(Hamilton, Ying, Leskovec, NeurIPS 2017)を皮切りに、不正検知とレコメンデーションの両方に**グラフニューラルネットワーク(GNN)**が使われるようになった。
アイデア:ノードの特徴量を「自分の属性情報」と「近傍ノードの情報の集約」から学習する。
import torch
import torch.nn.functional as F
from torch_geometric.nn import SAGEConv
class GraphSAGE(nn.Module):
"""
GraphSAGE: 近傍ノードの情報をサンプリング・集約してノード表現を学習
"""
def __init__(self, in_channels: int, hidden_channels: int, out_channels: int):
super().__init__()
self.conv1 = SAGEConv(in_channels, hidden_channels)
self.conv2 = SAGEConv(hidden_channels, out_channels)
def forward(self, x, edge_index):
# 第1層:自身の特徴 + 1ホップ先の近傍情報を集約
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
# 第2層:1ホップ先の集約結果をさらに集約(2ホップの情報)
x = self.conv2(x, edge_index)
return x
# 不正検知への適用:
# - ノード特徴:アカウントの属性(年齢、取引額、地域など)
# - エッジ:共有IP、共有デバイス、送金関係
# - ラベル:既知の不正(1)/ 正常(0)
# → 2ホップ先の不正アカウントとのつながりを自動的に学習なぜ GNN が強力か:
従来の機械学習(特徴量ベース):
「このアカウントのIPは怪しいIPか?」← 単独の属性だけを見る
「2次元先の不正アカウントとつながっているか?」← 手動でグラフ特徴を設計する必要
GNN:
グラフ構造そのものを入力として、「どのつながり方が怪しいか」を自動的に学習する
→ k 層のネットワーク = k ホップ先の情報を自動的に統合
→ 手動での特徴エンジニアリングが不要グラフ活用のパターン比較
graph TD
Problem{グラフで解きたい問題} --> T1[「怪しさ」を伝播させたい]
Problem --> T2[重要なノードを見つけたい]
Problem --> T3[似ているノードを見つけたい]
Problem --> T4[コミュニティを見つけたい]
Problem --> T5[複雑なパターンを学習したい]
T1 --> A1[ラベル伝播]
T2 --> A2[PageRank]
T3 --> A3[協調フィルタリング<br/>行列分解]
T4 --> A4[Louvain法<br/>スペクトルクラスタリング]
T5 --> A5[GraphSAGE / GCN]まとめ
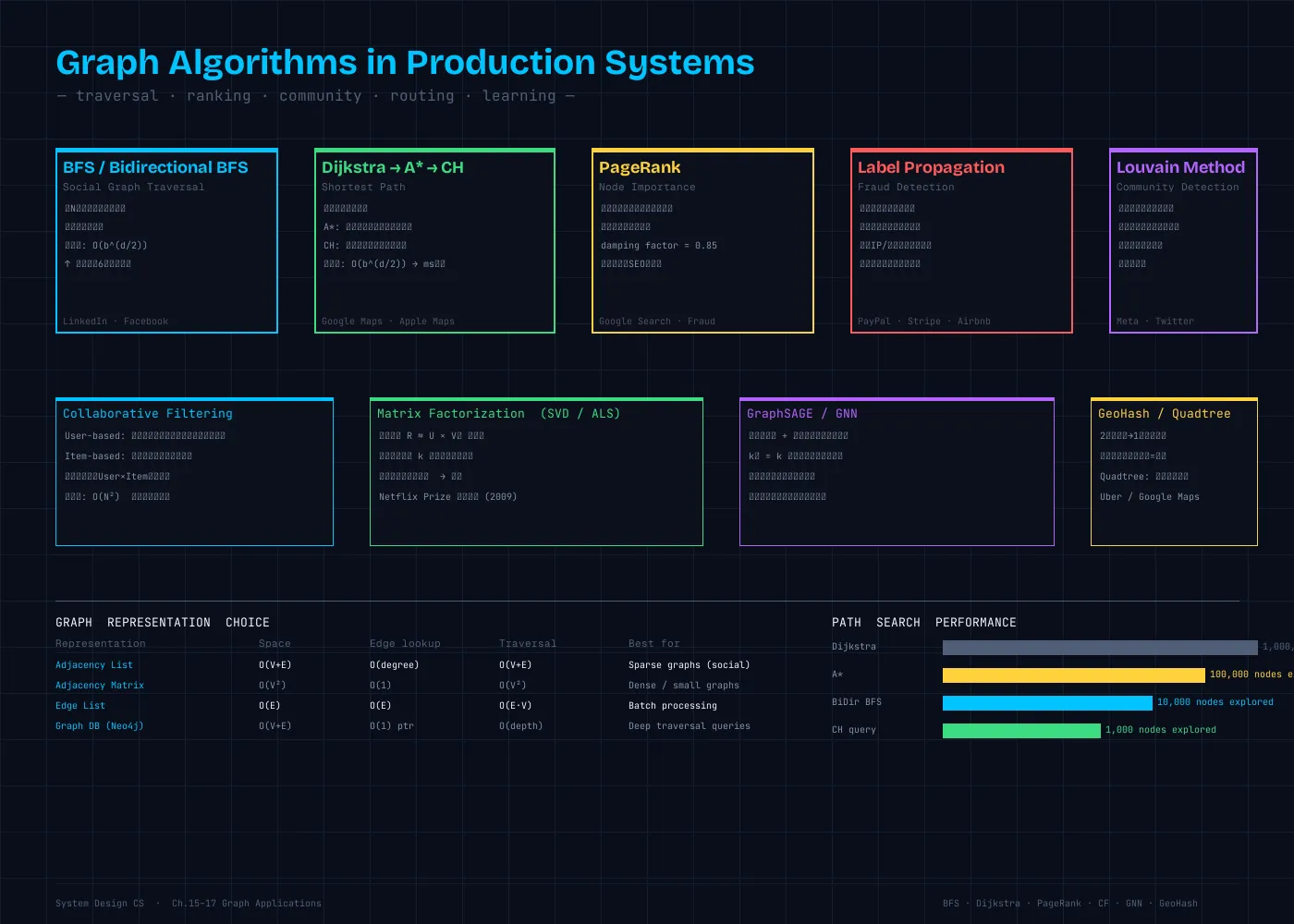
| 応用 | アルゴリズム | グラフの表現 | 適用できる問題 |
|---|---|---|---|
| 不正検知(スコア伝播) | ラベル伝播 | 同一属性でエッジ | 確定不正との近さ |
| 不正コミュニティ検出 | Louvain法 | エンティティグラフ | 組織的不正グループ |
| 影響力・重要度 | PageRank | 参照・リンクグラフ | 重要ノードの特定 |
| 「似ているユーザー」 | 協調フィルタリング | ユーザー×アイテム 二部グラフ | 人ベース推薦 |
| 潜在的な嗜好の発見 | 行列分解(MF) | 評価行列の分解 | 大規模推薦 |
| 複雑なグラフパターン | GraphSAGE(GNN) | 任意のグラフ | 属性+構造の統合学習 |
グラフが有効な問題の共通点:「孤立した点として見ると無害だが、つながりを見ると異常」なパターンが存在する問題。不正検知も推薦も、個々のデータポイントではなく関係性の中にシグナルが埋まっている点で同じ構造を持つ。