ロードバランサー ── L4 / L7・ヘルスチェック・サーキットブレーカー
扱うCS概念:OSI参照モデル(L4/L7)、ラウンドロビン / 加重ラウンドロビン / 最少接続 / 一貫性ハッシュ、ヘルスチェック、サーキットブレーカーパターン
この章で何ができるようになるか:L4 と L7 ロードバランサーの違いを動作原理から説明でき、トラフィックパターンに応じた負荷分散アルゴリズムを選択できるようになる。サーキットブレーカーの状態遷移を理解できる。
問題設定
「API サーバー10台にリクエストを均等に分配する」。シンプルに見えるが、考慮点は多い。
状況A:あるサーバーだけ GC で一時的に遅い → そこにリクエストが溜まる
状況B:WebSocket 接続が特定サーバーに集中 → セッションアフィニティが必要
状況C:下流サービスが障害 → 延々タイムアウト待ちで全体が連鎖障害
状況D:カナリアデプロイ → 新バージョンに5%だけ流したいL4 vs L7:どの層で振り分けるか
graph LR
subgraph L4ロードバランサー
direction TB
L4[TCP/UDPレベル<br/>IPアドレス・ポート番号のみ参照]
L4 --> |IP hash| S1[Server 1]
L4 --> |IP hash| S2[Server 2]
end
subgraph L7ロードバランサー
direction TB
L7[HTTP/gRPCレベル<br/>URL・ヘッダー・Cookie参照]
L7 --> |/api/users| S3[Users Service]
L7 --> |/api/orders| S4[Orders Service]
L7 --> |Cookie: session=X| S5[Sticky Session]
end| L4(トランスポート層) | L7(アプリケーション層) | |
|---|---|---|
| 参照する情報 | IP, ポート, TCP/UDP | URL, Host, ヘッダー, Cookie, Body |
| パフォーマンス | 非常に高速(パケット転送) | L4 より遅い(HTTP パース必要) |
| SSL 終端 | △ 可能(AWS NLB は2019年から TLS 終端に対応) | ✅ できる(TLS Offloading) |
| コンテンツベースルーティング | ❌ | ✅(/api/v2 → 新バージョンなど) |
| WebSocket | △(TCP を透過的に通す) | ✅(プロトコルを理解して制御) |
| 代表的な実装 | NLB (AWS), IPVS, LVS | ALB (AWS), Nginx, Envoy |
ℹ️ 補足: HAProxy は
mode tcp(L4)とmode http(L7)の両方をサポートし、設定で切り替え可能。L4/L7 どちらの用途にも使える汎用的なロードバランサーだ。
実務での使い分け:L4 を前段に置いて TCP 接続を分散し、後段に L7 を置いてコンテンツベースルーティングする2段構成が一般的。
インターネット → L4 NLB (TCP分散) → L7 Nginx/Envoy (HTTP路由) → バックエンドサーバー群負荷分散アルゴリズム
ラウンドロビン(Round Robin)
class RoundRobin:
def __init__(self, servers: list[str]):
self.servers = servers
self.index = 0
def next(self) -> str:
server = self.servers[self.index % len(self.servers)]
self.index += 1
return server- ✅ 最もシンプル
- ❌ サーバーの性能差を考慮しない
- ❌ リクエストの重さ(CPU 負荷)を考慮しない
加重ラウンドロビン(Weighted Round Robin)
class WeightedRoundRobin:
def __init__(self, servers: list[tuple[str, int]]):
# ("server1", 3) → server1 は重み3
self.pool = []
for server, weight in servers:
self.pool.extend([server] * weight)
self.index = 0
def next(self) -> str:
server = self.pool[self.index % len(self.pool)]
self.index += 1
return server
wrr = WeightedRoundRobin([
("large-instance", 5), # 高性能:リクエストの5/8
("medium-instance", 2), # 中性能:2/8
("small-instance", 1), # 低性能:1/8
])最少接続(Least Connections)
現在のアクティブ接続数が最も少ないサーバーに振り分ける。
class LeastConnections:
def __init__(self, servers: list[str]):
self.connections = {s: 0 for s in servers}
def next(self) -> str:
server = min(self.connections, key=self.connections.get)
self.connections[server] += 1
return server
def release(self, server: str):
self.connections[server] -= 1- ✅ 処理時間がばらつくリクエスト(動画エンコード、DB クエリ)に適切
- ❌ 新しく追加されたサーバー(接続0)に一気にリクエストが殺到する(Cold Start 問題)
一貫性ハッシュ(Consistent Hashing)
Ch.03 で扱った手法をロードバランサーに適用。同じリクエストキー(ユーザーID など)は常に同じサーバーに振り分けられる。
# セッションアフィニティの実現
def route_request(request) -> str:
key = request.headers.get("X-User-ID", request.remote_addr)
return consistent_hash_ring.get_server(key)- ✅ キャッシュ効率(同じユーザーは同じサーバーのローカルキャッシュを使える)
- ✅ WebSocket セッションのアフィニティ
- ❌ 特定ユーザーが重い処理をするとそのサーバーだけ負荷が高くなる
アルゴリズムの選択指針
| アルゴリズム | 向いているケース |
|---|---|
| ラウンドロビン | ステートレス API、リクエストの重さが均一 |
| 加重ラウンドロビン | サーバーのスペックに差がある |
| 最少接続 | 処理時間が大きくばらつく(動画処理・AI推論) |
| 一貫性ハッシュ | セッションアフィニティ、キャッシュ効率が重要 |
| ランダム | シンプルさが最優先、精度は不要 |
ヘルスチェック
障害サーバーにリクエストを送り続けると全体のレイテンシが悪化する。
class HealthChecker:
"""
Active Health Check: LB がサーバーに定期的にプローブを送る
"""
def __init__(self, servers: list[str], interval: int = 5):
self.servers = {s: {"healthy": True, "failures": 0} for s in servers}
self.interval = interval
self.failure_threshold = 3
self.recovery_threshold = 2
async def check_loop(self):
while True:
for server in self.servers:
try:
resp = await http_get(f"http://{server}/health", timeout=2)
if resp.status_code == 200:
self._mark_success(server)
else:
self._mark_failure(server)
except (ConnectionError, TimeoutError):
self._mark_failure(server)
await asyncio.sleep(self.interval)
def _mark_failure(self, server: str):
s = self.servers[server]
s["failures"] += 1
if s["failures"] >= self.failure_threshold:
s["healthy"] = False # プールから除外
def _mark_success(self, server: str):
s = self.servers[server]
s["failures"] = 0
s["successes"] = s.get("successes", 0) + 1
if s["successes"] >= self.recovery_threshold:
s["healthy"] = True # プールに復帰Active vs Passive ヘルスチェック:
Active:LB が /health を定期ポーリング。障害検知に数秒〜数十秒。
Passive:実際のリクエストの成功/失敗を観測。即座に反応できるが、誤判定リスクあり。
実務:両方を併用。Passive で即座に除外し、Active で復帰を判定。サーキットブレーカー
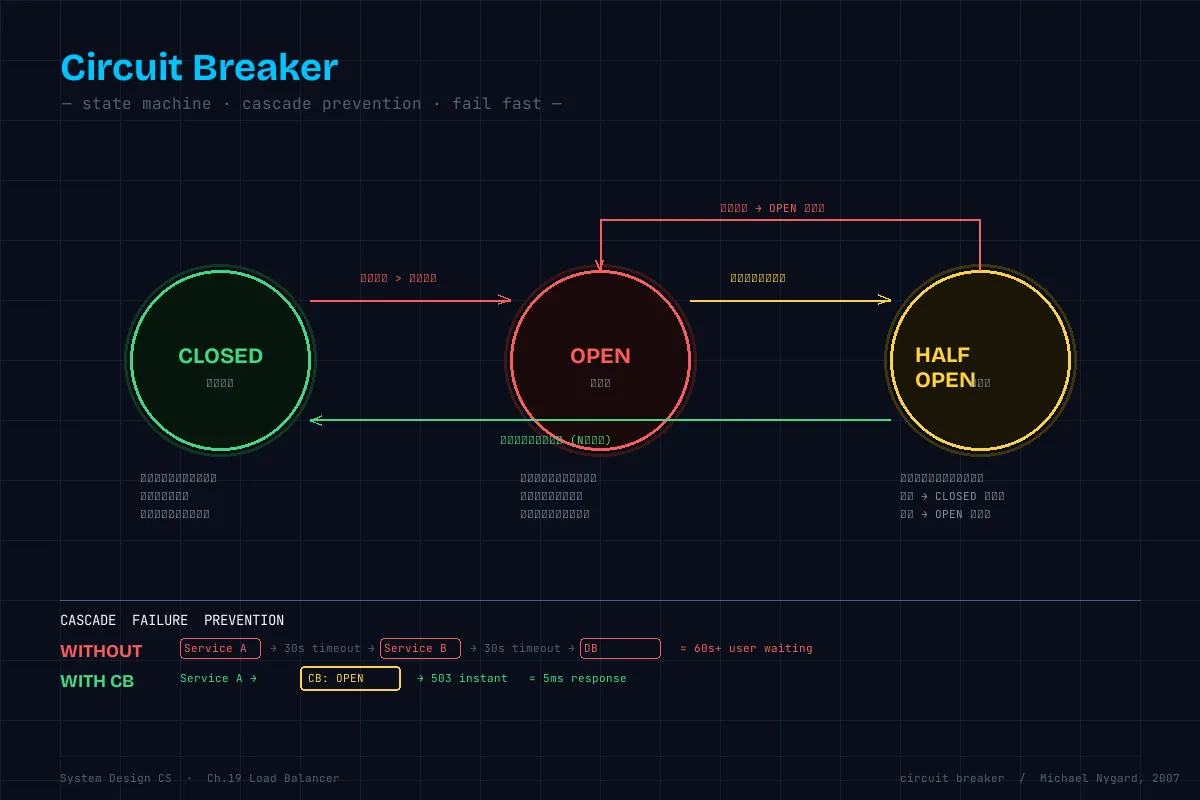
下流サービスの障害が上流に伝播する(カスケード障害)のを防ぐパターン。
stateDiagram-v2
[*] --> Closed
Closed --> Open: エラー率がしきい値超過
Open --> HalfOpen: タイムアウト経過
HalfOpen --> Closed: 試行リクエスト成功
HalfOpen --> Open: 試行リクエスト失敗import time
from enum import Enum
class CircuitState(Enum):
CLOSED = "closed" # 正常:リクエストを通す
OPEN = "open" # 遮断:即座にエラーを返す
HALF_OPEN = "half_open" # 試行:1件だけ通して確認
class CircuitBreaker:
def __init__(self, failure_threshold: int = 5,
recovery_timeout: int = 30,
success_threshold: int = 3):
self.state = CircuitState.CLOSED
self.failure_count = 0
self.success_count = 0
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.success_threshold = success_threshold
self.last_failure_time = 0
def call(self, func, *args, **kwargs):
if self.state == CircuitState.OPEN:
if time.time() - self.last_failure_time > self.recovery_timeout:
self.state = CircuitState.HALF_OPEN
else:
raise CircuitOpenError("Circuit is OPEN. Failing fast.")
try:
result = func(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise
def _on_success(self):
if self.state == CircuitState.HALF_OPEN:
self.success_count += 1
if self.success_count >= self.success_threshold:
self.state = CircuitState.CLOSED
self.failure_count = 0
self.success_count = 0
else:
self.failure_count = 0
def _on_failure(self):
self.failure_count += 1
self.last_failure_time = time.time()
self.success_count = 0
if self.failure_count >= self.failure_threshold:
self.state = CircuitState.OPEN
# 使用例
cb = CircuitBreaker(failure_threshold=5, recovery_timeout=30)
def call_payment_service(order):
return cb.call(requests.post, "http://payment-svc/charge", json=order)
# 5回連続失敗 → OPEN → 30秒間は即座にエラーを返す
# → 30秒後に HALF_OPEN → 1件通してみる → 成功なら CLOSED に復帰なぜ「即座にエラーを返す」のが良いのか:
サーキットブレーカーなし:
障害サーバーへのリクエストがタイムアウト(30秒)待ち
→ スレッド/コネクションプールを占有
→ 正常なリクエストも処理できなくなる(カスケード障害)
サーキットブレーカーあり:
即座にエラーを返す(数ms)
→ リソースが解放される
→ 正常なリクエストは影響を受けない
→ 障害サービスが回復したら自動的に復帰まとめ
| 設計判断 | 選択肢 | 判断基準 |
|---|---|---|
| ロードバランサーの層 | L4 / L7 / 2段構成 | コンテンツルーティングの要否 |
| 分散アルゴリズム | RR / WRR / 最少接続 / 一貫性ハッシュ | ステートレス vs ステートフル |
| ヘルスチェック | Active / Passive / 併用 | 検知速度 vs 誤判定リスク |
| 障害伝播の防止 | サーキットブレーカー | 下流依存サービスの信頼度 |
| SSL 終端 | LB で終端 / バックエンドまで通す | セキュリティ要件 vs パフォーマンス |