分散データベース(AlloyDB / Spanner) ── ゼロダウンタイムとレプリケーション
扱うCS概念:MVCC、Paxos/Raft、WAL(Write-Ahead Log)、論理レプリケーション、TrueTime
この章で何ができるようになるか:データベースのゼロダウンタイム更新・フェイルオーバーがどういう仕組みで実現されているか、強整合性のまま複数リージョンに分散する際のトレードオフを説明できるようになる。
問題設定
データベースの運用で最も怖いのは「更新時のダウンタイム」だ。
シナリオ1:プライマリノードのOS更新
→ 素朴な方法:DB停止 → 更新 → 再起動(数分〜十数分のダウン)
シナリオ2:スキーマ変更(大テーブルへのインデックス追加)
→ 素朴な方法:ALTER TABLE → ロック → テーブル全件スキャン(数時間のダウン)
シナリオ3:東京リージョンの障害時に大阪リージョンへ切り替え
→ 素朴な方法:手動でフェイルオーバー → 数分以上のダウン+データロスGoogle の AlloyDB(PostgreSQL 互換)や Cloud Spanner はこれらを「ほぼゼロダウンタイム」で実現している。どうやっているのか。
MVCC:読み書きが互いをブロックしない仕組み
多くのダウンタイムの原因はロック競合だ。「書き込み中は読み込み禁止」という単純なロック戦略だと、書き込みが長引くと読み込みが全てブロックされる。
**MVCC(Multi-Version Concurrency Control)**はこれを解決する。
考え方は「過去のスナップショットを保持する」こと。
時刻 T1 に書き込み開始:
row_id=1, value="旧データ", version=T0 → HIDDEN(古いバージョン)
row_id=1, value="新データ", version=T1 → 書き込み中
時刻 T0 時点のスナップショットで読み込みを開始したトランザクション:
→ version=T0 以下のデータを読む → "旧データ" を返す(ブロックなし)
書き込みが T2 にコミット:
→ version=T2 以降のトランザクションは "新データ" を読むsequenceDiagram
participant W as 書き込みTx (T1)
participant DB as DB(MVCCあり)
participant R as 読み込みTx (T0スナップショット)
W->>DB: BEGIN (T1)
W->>DB: UPDATE row=1 ("新データ") → 新バージョン作成
R->>DB: SELECT row=1 → T0スナップショット参照
DB->>R: "旧データ" を返す(ブロックなし)
W->>DB: COMMIT → T2
R->>DB: SELECT row=1 → T0スナップショット参照(変わらず)
DB->>R: "旧データ" を返す(トランザクション完了まで一貫性)PostgreSQL / MySQL InnoDB / Oracle など主要 RDBMS はほぼ全て MVCC を実装している。
Vacuum / Garbage Collection:古いバージョンが溜まり続けるとストレージを圧迫する。PostgreSQL の VACUUM や MySQL のパージスレッドが不要なバージョンを定期的に削除する。
WAL(Write-Ahead Log):ゼロダウンタイムの基盤
**WAL(Write-Ahead Log、先行書き込みログ)**は、データを変更する前に「これから何をするか」をログに書いておく仕組みだ。
書き込み操作の順序:
1. WAL に「この変更をする予定」を書き込む(ディスクに fsync)
2. メモリ上のデータページを変更
3. 一定タイミングでデータページをディスクに書き出す(checkpoint)
クラッシュ時の復旧:
WAL を読み直して、コミット済みの変更を再適用(redo)
未コミットの変更を巻き戻す(undo)これにより:
- クラッシュしてもデータは失われない(WAL がある限り復元できる)
- WAL をストリーミングして別サーバーに転送すれば、レプリケーションが実現できる
WAL ベースのレプリケーション
graph LR
Primary --> WAL[(WAL)]
WAL -->|WALストリーミング| Replica1[レプリカ1<br/>同一リージョン]
WAL -->|WALストリーミング| Replica2[レプリカ2<br/>別リージョン]
Replica1 --> Apply1[WAL適用<br/>→ データ同期]
Replica2 --> Apply2[WAL適用<br/>→ データ同期]同期レプリケーション:プライマリはレプリカが WAL を受け取ったことを確認してからコミットを返す。データロスなし、レイテンシが増加。
非同期レプリケーション:プライマリはすぐにコミットを返し、レプリカへの転送はバックグラウンド。レイテンシ低、フェイルオーバー時にわずかなデータロスが起きうる(RPO > 0)。
AlloyDB のアーキテクチャ
AlloyDB は「PostgreSQL 互換の高性能マネージド DB」として 2022年に Google が発表した。その設計は Aurora(AWS)と似た「コンピュート・ストレージ分離」を採用しつつ、独自の最適化を施している。
graph TD
subgraph コンピュート層
Primary[プライマリインスタンス<br/>Read/Write]
ReadReplica1[読み取りレプリカ 1]
ReadReplica2[読み取りレプリカ 2]
end
subgraph ストレージ層(Google の分散ストレージ)
LogStore[ログストア<br/>WALのみ保持]
PageStore[ページストア<br/>実データページ]
end
Primary -->|WAL書き込み| LogStore
LogStore -->|非同期でページ変換| PageStore
ReadReplica1 -->|WAL読み取り| LogStore
ReadReplica2 -->|ページ読み取り| PageStoreキーポイント:
-
ログの物理共有:プライマリと全レプリカが同一のログストレージを参照する。プライマリが書いた WAL を、レプリカはネットワーク越しに転送するのではなく、共有ストレージから直接読む。これにより複数レプリカへの転送オーバーヘッドが消える。
-
ページ生成をストレージ層へ:通常の PostgreSQL では「WAL → ページ」の変換をインスタンスが行う。AlloyDB はこれをストレージ層のバックグラウンドで行う。コンピュート層は WAL の書き込みに集中でき、CPU が解放される。
-
コールドスタートが速い:新しいレプリカを追加するとき、データを全コピーする必要がない。共有ストレージのページを直接読むだけで起動できる。
ゼロダウンタイムフェイルオーバー
AlloyDB のフェイルオーバーが速い理由:
従来の PostgreSQL フェイルオーバー:
1. プライマリ障害検知(30秒〜数分)
2. 最新レプリカを新プライマリに昇格
3. 未適用の WAL をレプリカに追いつかせる(数十秒〜数分)
4. アプリケーションの接続先切り替え
合計:数分以上
AlloyDB のフェイルオーバー:
1. 障害検知(秒単位)
2. レプリカがすでに共有ストレージの最新 WAL を参照済み → 「追いつき」が不要
3. 新プライマリが共有ストレージへの書き込み権限を取得
4. DNS 切り替え(アプリケーション透過)
合計:60秒以内(公称)なぜ「追いつき」が不要なのか:コンピュート・ストレージ分離の恩恵だ。ストレージは分散システムとして常に最新状態を保っており、どのコンピュートインスタンスも最新のデータにアクセスできる。プライマリが「自分の手元のキャッシュ」を持っているのではなく、全インスタンスが共通の真実(ストレージ)を参照している。
ゼロダウンタイムのスキーマ変更(pt-online-schema-change / gh-ost)
DB 本体の設計だけでなく、スキーマ変更をどう無停止で行うかも重要なトピックだ。
-- ❌ 素朴な ALTER TABLE(大テーブルでは数時間のロック)
ALTER TABLE orders ADD INDEX idx_user_id (user_id);**pt-online-schema-change(Percona)**や **gh-ost(GitHub)**は以下の手法でこれを解決する。
gh-ost の動作:
1. `orders_gho` という新テーブルを作成(新スキーマ)
2. `orders` から `orders_gho` へデータをバックグラウンドでコピー
3. `orders` への変更を binlog で監視 → `orders_gho` にも適用(追いかけ続ける)
4. コピーが追いついたら、一瞬だけロック → テーブル名を原子的にスワップ
5. `orders` → `orders_gho` に即座に切り替え完了sequenceDiagram
participant App as アプリケーション
participant Old as orders(旧テーブル)
participant New as orders_gho(新テーブル)
participant Ghost as gh-ost
App->>Old: 通常の Read/Write(継続)
Ghost->>New: バックグラウンドコピー開始
Ghost->>Old: binlog を監視(変更をキャプチャ)
Ghost->>New: コピー+変更の追従(同時進行)
Note over Ghost: コピー完了・追いついた
Ghost->>Old: 最小限のロック(ミリ秒)
Ghost->>Old: テーブル名スワップ(RENAME)
App->>Old: 透過的に新テーブルを参照ロックは最後の RENAME の一瞬(通常 1〜数秒)だけ。テーブルが数百GBあっても、ダウンタイムはほぼゼロだ。
Cloud Spanner と TrueTime:グローバル一貫性の実現
複数リージョンにまたがって**強整合性(Strong Consistency)**を保ちながらデータを分散する──これは分散システムの難問だ。
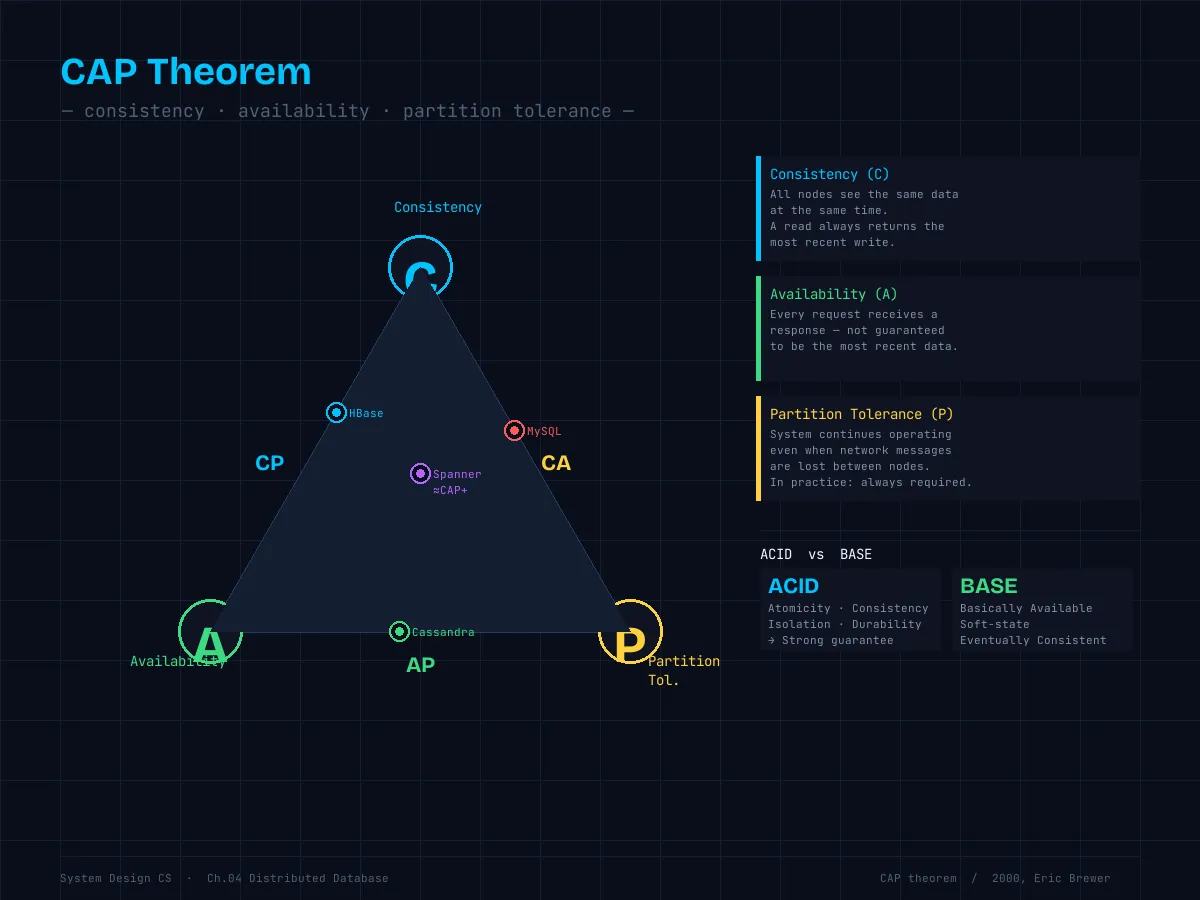
CAP定理:分散システムは「一貫性(C)」「可用性(A)」「分断耐性(P)」のうち、同時に全ては満たせない。
| システム | C | A | P |
|---|---|---|---|
| 伝統的 RDBMS(単一ノード) | ✅ | ✅ | ❌ |
| Cassandra | ❌(結果整合性) | ✅ | ✅ |
| Cloud Spanner | ✅ | ✅(高可用) | ✅ |
「Spanner は CAP 定理を破っているのか?」── 答えは No だ。Spanner は分断(P)が実際にはほぼ起きない高品質なプライベートネットワーク(Google のグローバルバックボーン)を使い、一貫性と可用性を実用上両立させている。理論的には CP に属する。
TrueTime:時刻の不確実性を武器にする
分散システムで「どのトランザクションが先か」を決めるには、時刻の一致が必要だ。しかし通常の NTP では数ミリ秒の誤差がある。
Google は TrueTime という仕組みを作った。
TrueTime API:
TT.now() → [earliest, latest] という区間を返す
「現在時刻は earliest と latest の間である」ことが保証される
誤差:通常 1〜7ms(GPS + 原子時計で実現。近年は p99 で 1ms 未満も達成)Spanner はトランザクションのコミット時に:
TT.now()を取得 → [t_earliest, t_latest]t_latestが確実に過ぎるまで 待つ(commit wait)- コミットタイムスタンプ = t_latest
これにより「より後にコミットされたトランザクションは、より大きなタイムスタンプを持つ」ことが保証される。地球の反対側のトランザクションとも順序が一致する。
sequenceDiagram
participant TX1 as TX1(東京)
participant TX2 as TX2(ニューヨーク)
participant Spanner
TX1->>Spanner: commit → TT.now() = [100, 114]
Note over TX1: t_latest=114 が過ぎるまで待機
TX1->>Spanner: コミット完了(TS=114)
TX2->>Spanner: commit → TT.now() = [115, 129]
TX2->>Spanner: コミット完了(TS=129)
Note over Spanner: TS 114 < 129 → TX1が先であることが保証Raft によるレプリカグループの合意
Spanner は内部で Paxos アルゴリズムを使い、複数レプリカ間の合意を取る(ここでは理解しやすい Raft で概念を説明する。Paxos と Raft は本質的に同等の合意アルゴリズムだ)。
Raft の基本:
- 1 つのリーダーと複数のフォロワーで構成
- 書き込みはリーダーが受け付け、過半数(quorum)の承認を得てコミット
- リーダーが落ちたら、フォロワーが選挙でリーダーを選出(数秒以内)
Spanner での適用:
- シャード(スプリット)ごとに Paxos グループが存在
- 各グループのリーダーが世界中に分散
- グローバルに均一な強整合性を確保# Raft のリーダー選出ロジック(擬似コード)
class RaftNode:
def __init__(self, node_id: int, peers: list):
self.node_id = node_id
self.peers = peers
self.state = "follower"
self.current_term = 0
self.voted_for = None
self.election_timeout = random.uniform(150, 300) # ms
def start_election(self):
self.current_term += 1
self.state = "candidate"
self.voted_for = self.node_id
votes = 1 # 自票
for peer in self.peers:
if peer.request_vote(self.current_term, self.node_id):
votes += 1
if votes > len(self.peers) / 2:
self.state = "leader"
self.send_heartbeats()
def append_entries(self, entries: list) -> bool:
# 過半数のフォロワーに書き込みを確認してからコミット
acked = 1
for peer in self.peers:
if peer.append(entries, self.current_term):
acked += 1
return acked > len(self.peers) / 2まとめ
| 課題 | 解決策 | 背景CS概念 |
|---|---|---|
| 読み書きのロック競合 | MVCC(複数バージョン保持) | スナップショット分離 |
| クラッシュ時のデータ保全 | WAL(先行書き込みログ) | redo/undo ログ |
| レプリカへのデータ同期 | WAL ストリーミング | ログベースレプリケーション |
| フェイルオーバーの高速化 | コンピュート・ストレージ分離 | 共有ストレージアーキテクチャ |
| 無停止スキーマ変更 | gh-ost(シャドウテーブル方式) | CDC + 原子的 RENAME |
| グローバル強整合性 | TrueTime + Commit Wait | 時刻区間を使った順序保証 |
| 分散合意 | Paxos / Raft | quorum ベースの合意アルゴリズム |
次章では、分散キャッシュ(Redis)がどうやって高速性と整合性のトレードオフを管理しているかを見ていく。