オブジェクトストレージ(S3)── 大規模トラフィックの捌き方
扱うCS概念:一貫性ハッシュ、イレイジャーコーディング、データ局所性、ハッシュパーティショニング、Bloom Filter
この章で何ができるようになるか:S3 が「落ちない」「遅くならない」ために使っている主要な設計技法を説明できるようになる。大規模オブジェクトストレージを自分で設計する際の考慮点を把握できる。
問題設定
「S3 のようなオブジェクトストレージを設計せよ」という面接問題は、以下の規模感を前提にすることが多い。
データ量:1エクサバイト(10^18 バイト)以上
オブジェクト数:1兆以上
1日のリクエスト数:数兆(S3 の公称値)
耐久性:99.999999999%(イレブンナイン)
可用性:99.99%
レイテンシ:小さなオブジェクトは数十ms 以内ここで「サーバーをたくさん並べればいい」という回答では足りない。たくさんのサーバーで構成されるシステムが、単一のサービスとして一貫して動くための仕組みが問われている。
素朴な設計とその限界
案1:単一サーバーに全データを置く
論外だが、なぜ論外かを言語化しておくと思考が整理される。
- ストレージ上限:1台のサーバーの物理的な限界(数十TB〜数PB)
- 障害時:全データアクセス不可
- スループット:1台のネットワーク帯域・IOPS の限界
案2:複数サーバーにファイルを分散(ランダム)
ランダムに分散しただけでは:
- あるオブジェクトがどのサーバーにあるかを調べるための「マップ」が必要
- そのマップ自体が大きくなりすぎる(1兆オブジェクトのマッピング)
- サーバーを追加・削除するたびにデータ移動が大量発生
この「サーバー構成変更時のデータ移動問題」を解決するのが**一貫性ハッシュ(Consistent Hashing)**だ。
CS概念の適用
一貫性ハッシュ(Consistent Hashing)
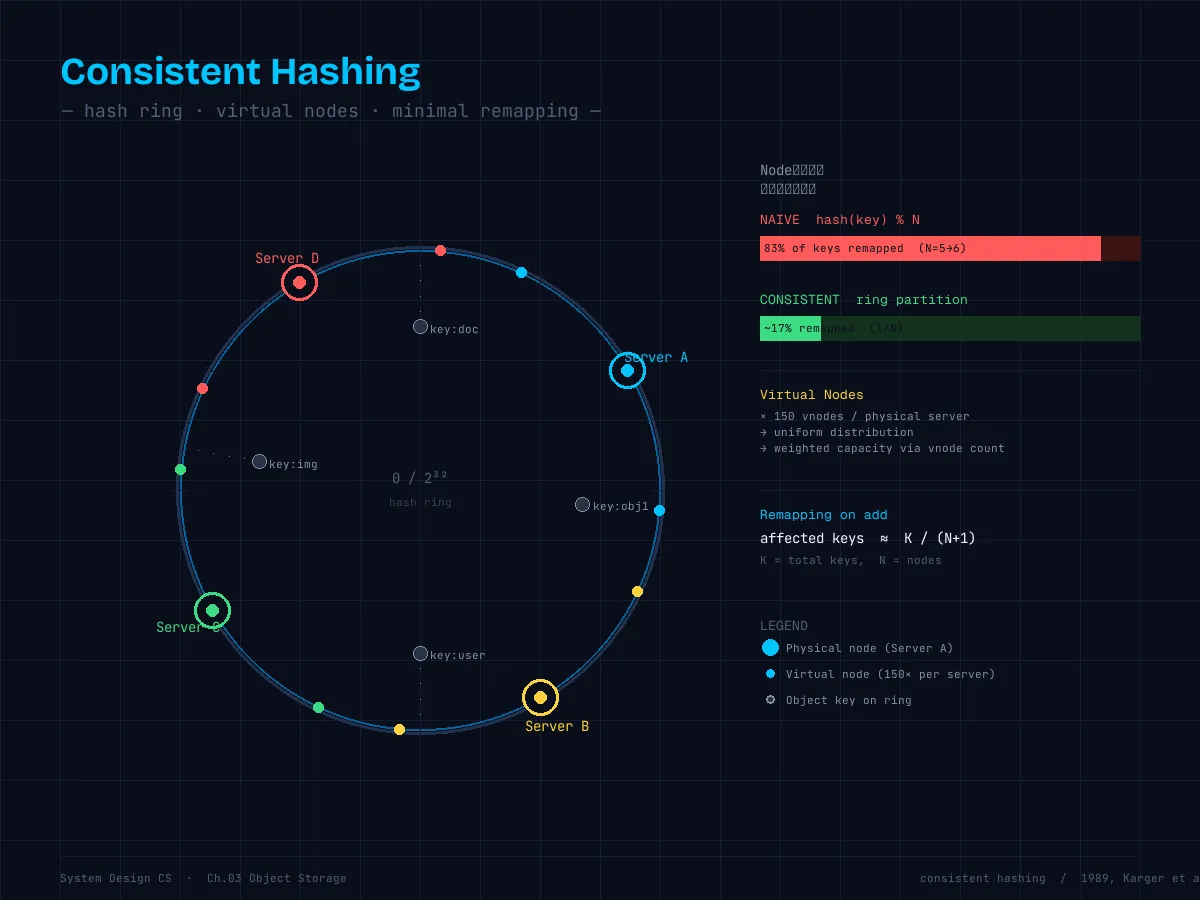
通常のハッシュ(node = hash(key) % N)の問題は、N(サーバー数)が変わるとほぼ全てのキーの配置先が変わることだ。
# N=5 のとき
hash("object_key") % 5 = 2 → サーバー2
# サーバーを1台追加して N=6 になると
hash("object_key") % 6 = 4 → サーバー4(!移動が必要)5 → 6 サーバーへの変更で、理論上 5/6 ≈ 83% のオブジェクトが移動対象になる。
一貫性ハッシュはこれを解決する。
graph LR
subgraph ハッシュリング 0〜360度
A[サーバーA<br/>@60°]
B[サーバーB<br/>@150°]
C[サーバーC<br/>@240°]
D[サーバーD<br/>@330°]
end
O1[Object1<br/>hash=80°] -.->|時計回りで最初のサーバー| B
O2[Object2<br/>hash=200°] -.-> C
O3[Object3<br/>hash=300°] -.-> D仕組み:
- 0 〜 $2^{32}-1$ の整数を円環(リング)とする
- サーバーをハッシュして円環上に配置
- オブジェクトをハッシュして円環上に配置し、時計回りで最初に見つかるサーバーに保存
サーバー追加時:そのサーバーと「前のサーバー」の間にあるオブジェクトだけが移動。影響範囲が 1/N に限定される。
import hashlib
from bisect import bisect, insort
class ConsistentHashRing:
def __init__(self, virtual_nodes: int = 150):
self.virtual_nodes = virtual_nodes # 仮想ノード数
self.ring: list[int] = []
self.nodes: dict[int, str] = {}
def _hash(self, key: str) -> int:
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def add_server(self, server: str):
# 仮想ノードを使って均一な分散を実現
for i in range(self.virtual_nodes):
hash_val = self._hash(f"{server}#{i}")
insort(self.ring, hash_val)
self.nodes[hash_val] = server
def get_server(self, key: str) -> str:
if not self.ring:
raise Exception("No servers available")
hash_val = self._hash(key)
idx = bisect(self.ring, hash_val) % len(self.ring)
return self.nodes[self.ring[idx]]
def remove_server(self, server: str):
for i in range(self.virtual_nodes):
hash_val = self._hash(f"{server}#{i}")
self.ring.remove(hash_val)
del self.nodes[hash_val]仮想ノード(Virtual Nodes):サーバー1台を複数のポイントとしてリングに配置することで、データの偏りを減らす。物理サーバーのスペック差(メモリ・CPU・ストレージ)に応じて仮想ノード数を調整することで、重み付き分散も実現できる。
イレイジャーコーディング(Erasure Coding)
「耐久性 99.999999999%(イレブンナイン)」を実現するにはどうするか。
素朴な解法はレプリケーション(複製)だ。3コピー持てば、1台壊れても2台残る。しかしストレージ効率が 1/3 になる。1エクサバイトのデータを保持するために 3エクサバイトのストレージが必要になる。
S3 が実際に使っているのはイレイジャーコーディングだ。
AWS re:Invent での公開情報によると、S3 は20シャード構成のイレイジャーコーディングを使用しており、ドライブサイズに応じて 17+3、16+4、15+5(データ+パリティ)の比率を使い分けている。
S3 の実際の構成例(17+3 方式):
17 個のデータチャンク + 3 個のパリティチャンク = 20 個のチャンク
20 個のうち 3 個が失われても、元の 17 個を復元できる
ストレージ効率:17/20 = 85%(オーバーヘッド約 18%)一般的なイレイジャーコーディングの仕組みを RS(14,10) を例に図解する:
graph TD
subgraph "イレイジャーコーディングの一般的な仕組み(RS(14,10) の例)"
Data[元データ 100MB] --> Split[10チャンク 10MB×10]
Split --> Encode[Reed-Solomon 符号化]
Encode --> D1[データ1] & D2[データ2] & D3...D10[データ3〜10]
Encode --> P1[パリティ1] & P2[パリティ2] & P3[パリティ3] & P4[パリティ4]
D1 & D2 & D3...D10 & P1 & P2 & P3 & P4 --> Nodes[14台の異なるノードへ]
end
subgraph 復元
Lost[4台が障害] --> Recover[残り10チャンクから復元可能]
endReed-Solomon 符号は CD/DVD のエラー訂正でも使われている古典的な符号理論だ。S3 はこれを分散ストレージに応用している。
ストレージ効率の比較
| 方式 | オーバーヘッド | 最大障害耐性 |
|---|---|---|
| 3レプリカ | 200% | 2台の障害まで |
| RS(6,3) | 100% | 3台の障害まで |
| RS(17,3)(S3 実構成) | 18% | 3台の障害まで |
| RS(16,4)(S3 実構成) | 25% | 4台の障害まで |
| RS(15,5)(S3 実構成) | 33% | 5台の障害まで |
S3 は可用性ゾーン(AZ)をまたいでチャンクを配置することで、AZ障害にも耐える。
データ局所性とホットスポット回避
「images/ フォルダに集中してアップロードされる」ような状況で、同じプレフィックスを持つオブジェクトが同じサーバーに集中すると、そこがボトルネックになる。
S3 が 2018年にデフォルト動作を変えた話
2018年以前、S3 のパフォーマンスガイドには「ランダムなプレフィックスを使え」という推奨があった。例えば:
❌ 悪い例(連番プレフィックス):
images/2026-01-01/photo001.jpg
images/2026-01-01/photo002.jpg ← 同じプレフィックスで同じシャードに集中
✅ 良い例(ランダムプレフィックス):
7f3a-images/2026-01-01/photo001.jpg
3b9c-images/2026-01-01/photo002.jpg ← 異なるシャードに分散2018年以降、S3 は内部的にプレフィックスごとに自動シャーディングを行うようになり、この推奨は不要になった。これはS3 が内部でキーのハッシュ値でなくプレフィックスの利用パターンを学習し、動的にシャード分割を行う仕組みに変わったためだ。
Bloom Filter による不要な I/O の削減
「このオブジェクトは存在するか?」というチェックを毎回ディスクアクセスで行うのはコストが高い。存在しないオブジェクトへのリクエスト(GET → 404 になるもの)でも DB や ストレージにアクセスが走る。
Bloom Filter は「確実に存在しない」か「おそらく存在する」かを O(1) かつメモリ効率よく判定できるデータ構造だ。
from bitarray import bitarray
import hashlib
class BloomFilter:
def __init__(self, size: int, hash_count: int):
self.size = size
self.hash_count = hash_count
self.bit_array = bitarray(size)
self.bit_array.setall(0)
def _hashes(self, item: str) -> list[int]:
result = []
for i in range(self.hash_count):
# 異なるシードで複数のハッシュを生成
h = int(hashlib.md5(f"{i}:{item}".encode()).hexdigest(), 16)
result.append(h % self.size)
return result
def add(self, item: str):
for idx in self._hashes(item):
self.bit_array[idx] = 1
def might_contain(self, item: str) -> bool:
return all(self.bit_array[idx] for idx in self._hashes(item))
# False → 確実に存在しない(False Negative は起きない)
# True → おそらく存在する(False Positive は起きうる)特性:
- False Negative(存在するのに「なし」と判定):絶対に起きない
- False Positive(存在しないのに「あり」と判定):小さな確率で起きる
大規模オブジェクトストレージでは、存在しないキーへの問い合わせに対してストレージアクセスを省略できる。誤判定(False Positive)でも「もしかしたらあるかも」と判定するだけで、実際にアクセスして確認するフォールバックがある。
⚠️ 検証注記: S3 が内部で Bloom Filter を使用しているかは AWS の公開情報では確認できていません。S3 の内部ストレージ(ShardStore)は LSM-Tree を採用しており、LSM-Tree では Bloom Filter が一般的に使われますが、S3 での具体的な利用は推測の域を出ません。
S3 の内部アーキテクチャ(公開情報ベース)
AWS re:Invent の発表や Werner Vogels のブログから明らかになっている S3 の設計:
graph TD
Client --> ELB[ロードバランサー]
ELB --> Front[フロントエンドサービス<br/>認証・認可・リクエストルーティング]
Front --> Meta[メタデータサービス<br/>オブジェクト情報・バケット設定]
Front --> Storage[ストレージサービス<br/>実際のデータ読み書き]
Meta --> MetaDB[(メタデータDB<br/>DynamoDB相当)]
Storage --> DataNode1[データノード群<br/>イレイジャーコーディング]
Storage --> DataNode2
Storage --> DataNode3フロントエンドサービス:リクエストを受け付け、認証・認可を行い、バックエンドにルーティングする。ステートレスなため水平スケールが容易。
メタデータサービス:「バケット名/オブジェクトキー → どのデータノードのどこにあるか」のマッピングを持つ。非常に高頻度でアクセスされるため、インメモリキャッシュが多段で存在する。
ストレージサービス:実際のバイト列を管理。データノードへのルーティングとイレイジャーコーディングで耐障害性を確保する。
⚠️ 検証注記: S3 の内部ルーティングに一貫性ハッシュが使われているかは、AWS の公開情報では確認できませんでした。2018年以降の公式情報では、S3 はプレフィックスベースのパーティショニング(利用パターンに基づく動的分割)を採用しています。本章の一貫性ハッシュの解説は分散ストレージの一般的な設計手法としてお読みください。
マルチパートアップロードの仕組み
5GB を超えるファイルを S3 にアップロードするとき、マルチパートアップロードが必須となる(100MB 以上から推奨。各パートの最小サイズは 5MB)。
import boto3
s3 = boto3.client('s3')
# 1. マルチパートアップロードの開始
response = s3.create_multipart_upload(Bucket='my-bucket', Key='large-file.bin')
upload_id = response['UploadId']
parts = []
chunk_size = 5 * 1024 * 1024 # 5MB
with open('large-file.bin', 'rb') as f:
part_number = 1
while chunk := f.read(chunk_size):
# 2. 各チャンクをアップロード
resp = s3.upload_part(
Bucket='my-bucket',
Key='large-file.bin',
PartNumber=part_number,
UploadId=upload_id,
Body=chunk
)
parts.append({'PartNumber': part_number, 'ETag': resp['ETag']})
part_number += 1
# 3. 全パートを結合して完成
s3.complete_multipart_upload(
Bucket='my-bucket',
Key='large-file.bin',
UploadId=upload_id,
MultipartUpload={'Parts': parts}
)なぜマルチパートか:
- ネットワーク障害で一部が失敗しても、そのパートだけ再送できる
- 複数パートを並列アップロードしてスループットを上げられる
- S3 内部で各パートを別ノードに分散保存し、後で論理的に結合する
まとめ
| 課題 | 解決策 | CS概念 |
|---|---|---|
| サーバー増減時のデータ移動 | 一貫性ハッシュ | Consistent Hashing |
| ストレージ効率と耐障害性の両立 | イレイジャーコーディング | Reed-Solomon 符号 |
| 特定キープレフィックスへの集中 | 動的シャーディング | ハッシュパーティショニング |
| 存在しないキーへの無駄な I/O | Bloom Filter | 確率的データ構造 |
| 大ファイルの効率的な転送 | マルチパートアップロード | チャンキング・並列化 |
次章では、AlloyDB がどうやってダウンタイムなしでノードを更新し、複数リージョンへのレプリケーションを実現しているかを見ていく。