ニュースフィード(Twitter/Instagram)── Fan-out とセレブ問題
扱うCS概念:Fan-out on Write / Fan-out on Read、グラフトラバーサル、優先度付きマージ、ハイブリッドアーキテクチャ
この章で何ができるようになるか:「投稿が自分のフォロワー全員のタイムラインに届く」という操作の背後にある2つの対立するアーキテクチャを説明できるようになる。セレブリティ問題がなぜ起き、どう解決されているかを理解できる。
問題設定
Twitter/X や Instagram のタイムラインを設計する、という問題だ。
要件:
- ユーザー数:3億人(月間アクティブ)
- フォロー関係:平均200人、最大5000万人(セレブ)
- 投稿数:1日5億件
- タイムライン表示:フォローしている人の投稿を新しい順に20件表示
- レイテンシ:タイムライン表示は200ms以内
制約の非対称性:
読み取り(タイムライン表示)>> 書き込み(投稿)
→ Read:Write ≈ 1000:1この「非対称性」がアーキテクチャの選択を支配する。
2つのアプローチ
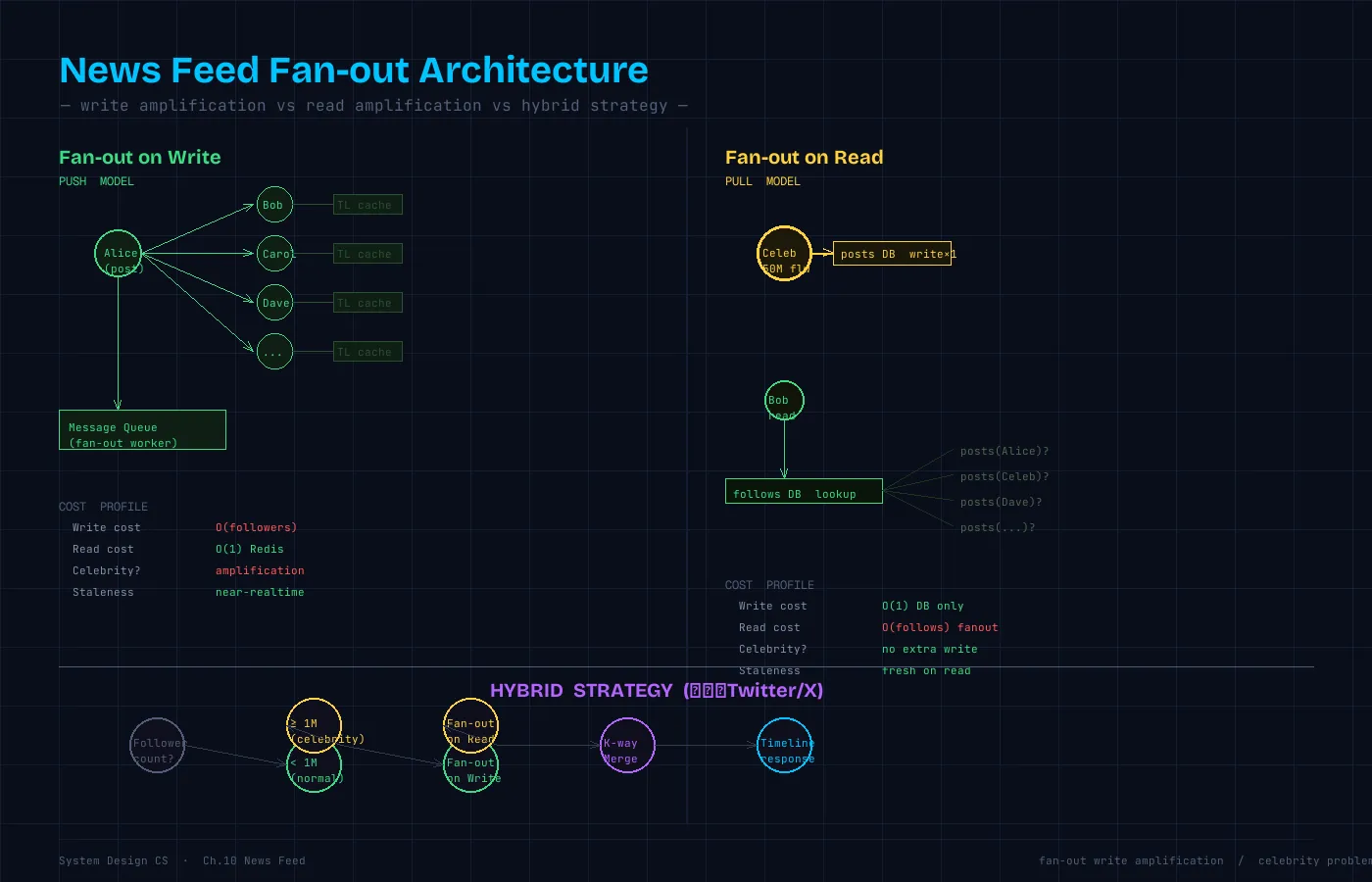
アプローチA:Fan-out on Write(プッシュモデル)
投稿した瞬間に、全フォロワーのタイムラインに書き込む。
def publish_post(user_id: int, content: str):
# 1. 投稿を DB に保存
post_id = db.insert("posts", {
"user_id": user_id,
"content": content,
"created_at": now()
})
# 2. フォロワー全員のタイムラインに非同期で書き込む
followers = db.query("SELECT follower_id FROM follows WHERE followee_id = ?", user_id)
for follower_id in followers:
# 各フォロワーの Redis タイムラインリストの先頭に追加
redis.lpush(f"timeline:{follower_id}", post_id)
redis.ltrim(f"timeline:{follower_id}", 0, 999) # 最新1000件だけ保持
def get_timeline(user_id: int, page: int = 0):
# タイムライン表示は Redis から直接読むだけ(超高速)
post_ids = redis.lrange(f"timeline:{user_id}", page*20, page*20+19)
return db.mget("posts", post_ids)sequenceDiagram
participant Alice
participant PostDB
participant Queue as メッセージキュー
participant Worker as Fan-outワーカー
participant RedisA as Redis(Bob のTL)
participant RedisB as Redis(Carol のTL)
Alice->>PostDB: 投稿保存
Alice->>Queue: fan-out イベント発行
Queue->>Worker: イベント消費
Worker->>RedisA: LPUSH timeline:Bob postID
Worker->>RedisB: LPUSH timeline:Carol postID
Note over RedisA,RedisB: 以降の読み取りは Redis から直接✅ 長所:タイムライン読み取りが O(1)(Redis の LRANGE)。読み取り専用パスに DB が不要。
❌ 短所:セレブ(フォロワー5000万人)が投稿すると5000万件の書き込みが一斉発生。Fan-out の完了まで時間がかかる(投稿が全フォロワーに届くまでのラグ)。
アプローチB:Fan-out on Read(プルモデル)
投稿時は何もしない。タイムライン表示のとき、フォロー一覧を引いて投稿を集める。
def publish_post(user_id: int, content: str):
# 投稿を DB に保存するだけ
db.insert("posts", {"user_id": user_id, "content": content})
def get_timeline(user_id: int):
# フォロー一覧を取得
followees = db.query(
"SELECT followee_id FROM follows WHERE follower_id = ?", user_id
)
# 各フォロイーの最新投稿を取得してマージ
all_posts = []
for followee_id in followees:
posts = db.query(
"SELECT * FROM posts WHERE user_id = ? ORDER BY created_at DESC LIMIT 20",
followee_id
)
all_posts.extend(posts)
# 時刻順にソートして上位20件を返す
return sorted(all_posts, key=lambda p: -p["created_at"])[:20]✅ 長所:書き込みはシンプル(DB に1件保存するだけ)。セレブの投稿でも書き込みコストは変わらない。
❌ 短所:タイムライン表示のたびに N 個(フォロー数)のクエリが走る。200人フォローしていれば200クエリ。レイテンシが高く、DB 負荷が大きい。
セレブ問題(Celebrity Problem)
Fan-out on Write の致命的な問題が「セレブリティ」だ。
Elon Musk(フォロワー2億人超)が1ツイートすると:
→ 2億件以上の Redis 書き込みが発生
→ これをリアルタイムに処理しようとすると数分かかる
→ その間に次のツイートが来る → 積み残しが爆発的に増えるハイブリッドアプローチ(実際の Twitter/X の設計)
実際の Twitter(X)はハイブリッドモデルを採用している。
一般ユーザー(フォロワー < しきい値 N):
→ Fan-out on Write(タイムライン読み取りを高速化)
セレブリティ(フォロワー >= N):
→ Fan-out on Read(セレブの投稿だけ読み取り時にプルする)
タイムライン表示時:
→ 自分のタイムライン(Fan-out on Write で書かれたもの)を取得
→ フォローしているセレブの投稿(Fan-out on Read でその場でプル)
→ 2つをマージして返すCELEBRITY_THRESHOLD = 1_000_000 # フォロワー100万以上はセレブ扱い
def publish_post(user_id: int, content: str):
post_id = db.insert("posts", {"user_id": user_id, "content": content})
follower_count = db.get_follower_count(user_id)
if follower_count < CELEBRITY_THRESHOLD:
# 一般ユーザー:全フォロワーに Fan-out
enqueue_fanout(post_id, user_id)
# セレブは何もしない(読み取り時にプル)
def get_timeline(user_id: int):
# 1. Fan-out on Write で作られたタイムラインを Redis から取得
cached_post_ids = redis.lrange(f"timeline:{user_id}", 0, 199)
# 2. フォローしているセレブの最新投稿をその場でプル
celebrity_followees = db.query("""
SELECT followee_id FROM follows
WHERE follower_id = ?
AND followee_id IN (SELECT user_id FROM users WHERE follower_count >= ?)
""", user_id, CELEBRITY_THRESHOLD)
celebrity_posts = []
for celeb_id in celebrity_followees:
posts = redis.lrange(f"user_posts:{celeb_id}", 0, 19)
celebrity_posts.extend(posts)
# 3. マージして時刻順にソート
all_posts = merge_sorted(cached_post_ids, celebrity_posts)
return all_posts[:20]graph TD
Timeline[タイムライン表示リクエスト]
Timeline --> FanoutTL[Fan-out で積まれた<br/>タイムライン Redis から取得]
Timeline --> CelebPosts[フォロー中セレブの<br/>最新投稿をプル]
FanoutTL --> Merge[優先度付きマージ<br/>K-way merge]
CelebPosts --> Merge
Merge --> Result[上位20件を返す]K-way マージ:複数ソート済みリストの効率的なマージ
タイムライン表示時に複数の投稿リスト(Fan-out キャッシュ + セレブのプル)を時刻順にマージする必要がある。
素朴にやると全件をリストに入れてソート → O(N log N)。しかし各リストはすでにソートされているため、ヒープを使って O(N log K)(K はリスト数)でできる。
import heapq
def k_way_merge(post_lists: list[list[dict]]) -> list[dict]:
"""
K 個のソート済みリストを時刻降順にマージする
"""
# ヒープに (負の時刻, リストインデックス, ポインタ, 投稿データ) を入れる
heap = []
iters = [iter(lst) for lst in post_lists]
for i, it in enumerate(iters):
post = next(it, None)
if post:
heapq.heappush(heap, (-post["created_at"], i, post))
result = []
while heap and len(result) < 20:
neg_ts, list_idx, post = heapq.heappop(heap)
result.append(post)
# 同じリストから次の投稿を取り出してヒープに追加
next_post = next(iters[list_idx], None)
if next_post:
heapq.heappush(heap, (-next_post["created_at"], list_idx, next_post))
return resultタイムラインのデータモデル
-- 投稿テーブル(シャーディング対象)
CREATE TABLE posts (
post_id BIGINT PRIMARY KEY, -- Snowflake ID(時刻順)
user_id BIGINT NOT NULL,
content TEXT,
media_urls JSON,
created_at TIMESTAMP,
INDEX idx_user_created (user_id, created_at DESC) -- セレブのプルに使う
);
-- フォロー関係(グラフ構造)
CREATE TABLE follows (
follower_id BIGINT,
followee_id BIGINT,
created_at TIMESTAMP,
PRIMARY KEY (follower_id, followee_id),
INDEX idx_followee (followee_id) -- 「誰が〇〇をフォローしているか」の検索に使う
);まとめ
| アーキテクチャ | 書き込みコスト | 読み取りコスト | 向いているケース |
|---|---|---|---|
| Fan-out on Write | 高(フォロワー数に比例) | O(1) | フォロワーが少ない一般ユーザー |
| Fan-out on Read | 低(DB に1件書くだけ) | 高(フォロー数に比例) | セレブリティ |
| ハイブリッド | 中 | 中 | 実際の大規模サービス |
設計のキーメッセージ:「書き込み時にやるか、読み取り時にやるか」のトレードオフは、アクセスパターンの非対称性(誰が多くフォローされているか)に応じて動的に切り替えることで解決する。