エピローグ ── RDB を「ブラックボックス」にしない
クエリの旅を振り返る
SELECT u.name, COUNT(o.id)
FROM users u JOIN orders o ON u.id = o.user_id
WHERE u.created_at > '2025-01-01'
GROUP BY u.name ORDER BY count DESC LIMIT 10;
この SQL は以下の旅をする:
Ch.2 パーサー → SQL テキストを構文木に変換
Ch.2 アナライザー → テーブル・カラムの検証、型チェック
Ch.2 プランナー → 統計情報をもとにコスト最小の実行計画を選択
(Hash Join? Nested Loop? Index Scan? Seq Scan?)
Ch.3 実行エンジン → Volcano モデルで計画を実行
Ch.4 インデックス → B-Tree で u.id, o.user_id を高速検索
Ch.5 ストレージ → 8KB ページからタプルを読み出し
Ch.6 MVCC → 各タプルの可視性を t_xmin/t_xmax で判定
Ch.5 バッファ → shared_buffers でページをキャッシュ
Ch.7 WAL → COMMIT 時に WAL を fsyncチューニングのチェックリスト
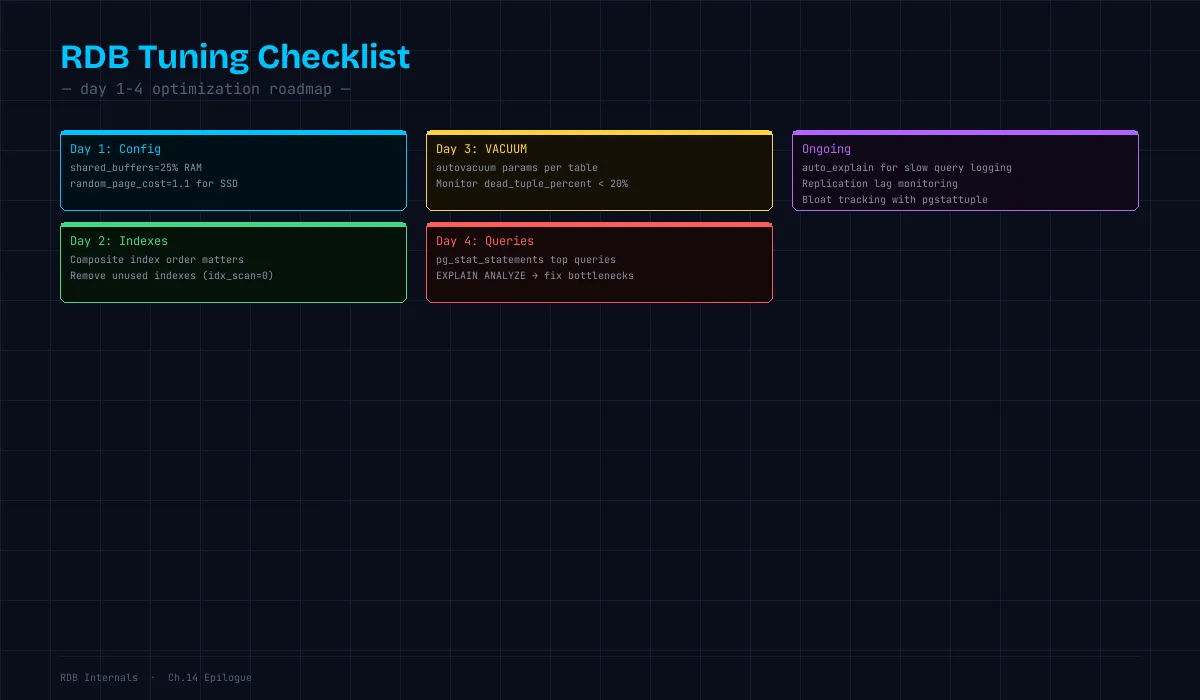
Day 1:基本設定
-- shared_buffers: 物理メモリの 25%
ALTER SYSTEM SET shared_buffers = '4GB'; -- 16GB RAM の場合
-- effective_cache_size: OS キャッシュ含めた利用可能メモリ(75%)
ALTER SYSTEM SET effective_cache_size = '12GB';
-- work_mem: ソート・ハッシュに使うメモリ(接続数を考慮)
ALTER SYSTEM SET work_mem = '64MB';
-- 注意: 1クエリ内で複数のソートが走ると、それぞれ work_mem を使う
-- maintenance_work_mem: VACUUM, CREATE INDEX に使うメモリ
ALTER SYSTEM SET maintenance_work_mem = '512MB';
-- SSD の場合
ALTER SYSTEM SET random_page_cost = 1.1; -- デフォルト 4.0 は HDD 向け
ALTER SYSTEM SET effective_io_concurrency = 200; -- SSD は並列I/O が得意Day 2:インデックス
□ 頻出クエリの WHERE 句にインデックスがあるか
□ JOIN のキーにインデックスがあるか
□ 複合インデックスの順序は最適か(高カーディナリティを先頭に)
□ 使われていないインデックスはないか(pg_stat_user_indexes で確認)
□ Index Only Scan が使える場面でカバリングインデックスを作ったか-- 使われていないインデックスの検出
SELECT
schemaname, relname AS table, indexrelname AS index,
idx_scan AS times_used,
pg_size_pretty(pg_relation_size(indexrelid)) AS size
FROM pg_stat_user_indexes
WHERE idx_scan = 0
ORDER BY pg_relation_size(indexrelid) DESC;Day 3:VACUUM と Bloat
□ autovacuum は動いているか
□ Dead Tuple の割合は 20% 以下か
□ 長時間トランザクションがないか
□ idle_in_transaction_session_timeout を設定したか
□ 更新が激しいテーブルのautovacuum パラメータをカスタマイズしたかDay 4:クエリ最適化
□ pg_stat_statements で遅いクエリを特定したか
□ EXPLAIN ANALYZE で実行計画を確認したか
□ 推定行数と実際の行数が大きくずれていないか
□ OFFSET ページネーションを Keyset に置き換えたか
□ SELECT * を必要カラムだけに絞ったか-- pg_stat_statements で遅いクエリを特定
CREATE EXTENSION pg_stat_statements;
SELECT
calls,
ROUND(total_exec_time::numeric, 2) AS total_ms,
ROUND(mean_exec_time::numeric, 2) AS avg_ms,
ROUND((100 * total_exec_time / SUM(total_exec_time) OVER())::numeric, 2) AS pct,
LEFT(query, 80) AS query
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 20;他のシリーズとの接続
RDB Internals → 他のシリーズ
Ch.4 B-Tree インデックス → CS Fundamentals Ch.10(B-Tree/LSM-Tree)
Ch.6 MVCC → System Design Ch.4(AlloyDB/Spanner)
Ch.7 WAL → System Design Ch.4(レプリケーションの基盤)
Ch.8 ロック → System Design Ch.18(分散ロック)
Ch.12 レプリケーション → System Design Ch.4(AlloyDB の設計)
Ch.13 パーティショニング → System Design Ch.13(シャーディング)参考文献
書籍
- The Internals of PostgreSQL — Hironobu SUZUKI(無料オンライン書籍。日本語あり)
- PostgreSQL 14 Internals — Egor Rogov(PostgreSQL コア開発者による解説)
- High Performance PostgreSQL for Rails — Andrew Atkinson
- Designing Data-Intensive Applications — Martin Kleppmann(Ch.3, 7 が特に関連)
公式ドキュメント
- PostgreSQL Documentation(世界最高品質の DB ドキュメント)
- pg_stat_statements
- EXPLAIN の読み方
最後に
RDB は「SQL を書けば答えが返ってくる魔法の箱」ではない。内部には何十年もかけて練り上げられた精巧なエンジニアリングが詰まっている。
その内部構造を知ることで、「なぜ遅いか」「どう直すか」「この設計で問題ないか」を自分の頭で判断できるようになる。EXPLAIN ANALYZE の出力が読めるようになった瞬間、RDB との付き合い方が根本的に変わるはずだ。