プロローグ ── SELECT 文の裏側で何が起きているか
シリーズ構成(全14章)
Part 1 — クエリの一生 Ch.1 プロローグ(本章) / Ch.2 パーサーとプランナー / Ch.3 実行エンジンとアクセスメソッド / Ch.4 インデックス深掘り — B-Tree・GIN・GiST・BRIN
Part 2 — ストレージとトランザクション Ch.5 ストレージエンジン — ページ・タプル・TOAST / Ch.6 MVCC — 読み書きが互いをブロックしない仕組み / Ch.7 WAL と障害復旧 / Ch.8 ロックとデッドロック
Part 3 — パフォーマンスチューニング Ch.9 EXPLAIN ANALYZE 完全ガイド / Ch.10 クエリ最適化のパターン集 / Ch.11 VACUUM と Bloat 対策
Part 4 — スケールと運用 Ch.12 レプリケーション — ストリーミング・ロジカル / Ch.13 パーティショニングとシャーディング / Ch.14 エピローグ
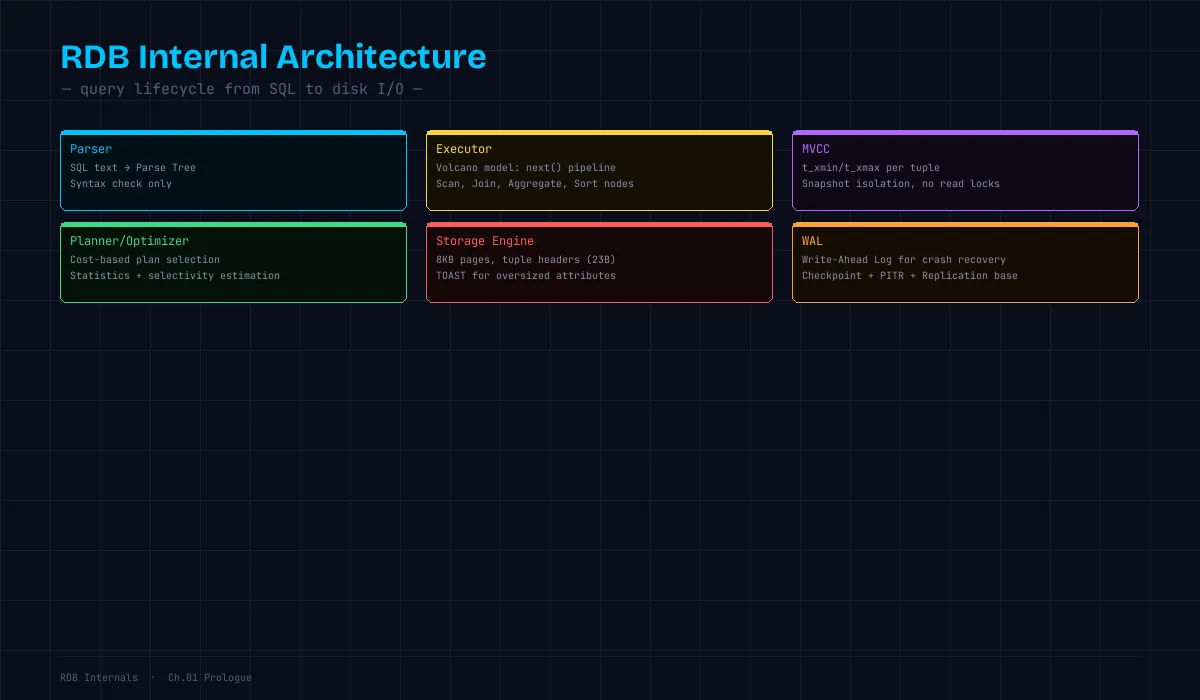
この記事で何を扱うか
SELECT u.name, COUNT(o.id) AS order_count
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.created_at > '2025-01-01'
GROUP BY u.name
ORDER BY order_count DESC
LIMIT 10;このクエリを実行したとき、データベースの内部では何が起きているのか。
1. SQL テキストが「構文木」に変換される(パーサー)
2. 構文木が「実行計画」に変換される(プランナー / オプティマイザ)
3. 実行計画に従ってデータが読み出される(実行エンジン)
4. ディスク上のページからタプルが取り出される(ストレージエンジン)
5. インデックスがあればそれを使ってスキャンを高速化する
6. MVCC がトランザクション間の可視性を制御する
7. WAL が障害時のデータ保全を担う
8. 結果がクライアントに返されるこのシリーズでは、クエリが通るこの「道筋」を上から下まで追いかけ、各レイヤーの仕組みを解説する。
対象読者
対象:RDB を日常的に使っているバックエンドエンジニア
「EXPLAIN は見たことあるけど、読み方がわからない」という方
「インデックスを貼ればいいんでしょ」からもう一段深く理解したい方
難易度:★★★★☆
読了時間:約5時間(全章通読時)
前提知識:基本的な SQL が書ける、テーブル設計の経験があるなぜ内部構造を知るべきか
場面1: 「このクエリ、なぜ遅いの?」
→ EXPLAIN ANALYZE の出力が読めなければ原因がわからない
→ Seq Scan が起きている理由がわからない
場面2: 「インデックスを貼ったのに速くならない」
→ インデックスの種類(B-Tree? GIN? BRIN?)の選択が間違っている
→ そもそもインデックスが使われない条件がある
場面3: 「テーブルが肥大化して性能が劣化した」
→ VACUUM の仕組みを理解していないと対処できない
→ Dead Tuple の蓄積(Bloat)の原因がわからない
場面4: 「レプリケーション遅延でデータが不整合」
→ ストリーミングレプリケーションの仕組みを知らないと判断できないPostgreSQL を例にする理由
1. オープンソースで内部実装が読める
2. ドキュメントが充実しており、内部動作の解説が豊富
3. エンタープライズでの採用が急増(2020年代の事実上の標準OSS RDB)
4. 拡張性が高く、インデックスタイプが豊富(B-Tree, GIN, GiST, BRIN, SP-GiST)
5. MVCC の実装が教育的(MySQL InnoDB とは異なるアプローチ)ただし、概念(B-Tree インデックス、MVCC、WAL、実行計画)は全ての RDBMS に共通する。MySQL、Oracle、SQL Server を使っていても、このシリーズの知識は直接活きる。
RDB の内部アーキテクチャ全体像
クライアント
↓ SQL テキスト
┌──────────────────────────────────────┐
│ パーサー(Parser) │
│ → SQL → 構文木(Parse Tree) │
├──────────────────────────────────────┤
│ アナライザー / リライター │
│ → 構文木 → クエリツリー │
├──────────────────────────────────────┤
│ プランナー / オプティマイザ │
│ → クエリツリー → 実行計画(Plan Tree)│
│ → コスト推定でベストな計画を選択 │
├──────────────────────────────────────┤
│ 実行エンジン(Executor) │
│ → 実行計画を実行し、結果を返す │
├──────────────────────────────────────┤
│ アクセスメソッド(Access Methods) │
│ → テーブルスキャン / インデックススキャン│
├──────────────────────────────────────┤
│ バッファマネージャー │
│ → ディスクページのキャッシュ管理 │
│ → shared_buffers │
├──────────────────────────────────────┤
│ ストレージエンジン │
│ → ページ / タプル / TOAST │
│ → WAL(Write-Ahead Log) │
│ → MVCC(多版型同時実行制御) │
└──────────────────────────────────────┘
↓↑ ディスク I/O
ファイルシステム / ディスクこのシリーズの読み方
各章は以下の流れで書いている。
1. その層が「何をしているか」(役割の説明)
2. 内部でどう動いているか(図解とコード)
3. PostgreSQL での具体的な確認方法(実際のコマンド)
4. パフォーマンスへの影響と最適化のポイント
5. 他の RDBMS との比較(MySQL InnoDB など)では、クエリの旅の始まり──パーサーとプランナーから出発しよう。