パーサーとプランナー ── SQL が実行計画になるまで
このレイヤーの役割:SQL テキストを構文解析し、最適な実行計画を選択する。RDB の「頭脳」。
この章で何ができるようになるか:SQL が「テキスト → 構文木 → 実行計画」と変換される過程を理解し、プランナーが「なぜこの実行計画を選んだか」を推測できるようになる。
フェーズ1:パーサー(Parser)
SQL テキストを**構文木(Parse Tree)**に変換する。プログラミング言語のコンパイラのフロントエンドと同じ。
SELECT name FROM users WHERE age > 30;構文木:
SelectStmt
├── targetList: [ColumnRef "name"]
├── fromClause: [RangeVar "users"]
└── whereClause:
└── A_Expr (>)
├── left: ColumnRef "age"
└── right: Const 30パーサーが検出するエラー:構文エラーのみ。テーブルやカラムの存在チェックはまだ行わない。
-- パーサーが弾く(構文エラー)
SELCT name FORM users;
-- パーサーは通す(構文は正しい)が、アナライザーで弾かれる
SELECT name FROM nonexistent_table;フェーズ2:アナライザー(Analyzer)
構文木の意味を解析する。テーブルの存在確認、カラムの型チェック、暗黙の型変換を行う。
SELECT name FROM users WHERE age > '30';
-- '30' は TEXT 型だが、age が INTEGER なら暗黙的に INTEGER にキャスト
-- → アナライザーが型変換ノードを挿入フェーズ3:リライター(Rewriter)
ビューの展開やルールの適用を行う。
-- ビュー定義
CREATE VIEW active_users AS
SELECT * FROM users WHERE status = 'active';
-- ユーザーのクエリ
SELECT name FROM active_users WHERE age > 30;
-- リライト後(ビューが展開される)
SELECT name FROM users WHERE status = 'active' AND age > 30;フェーズ4:プランナー / オプティマイザ(Planner)
最も重要なフェーズ。クエリツリーから**実行計画(Plan Tree)**を生成する。複数の計画候補を生成し、コスト推定でベストなものを選ぶ。
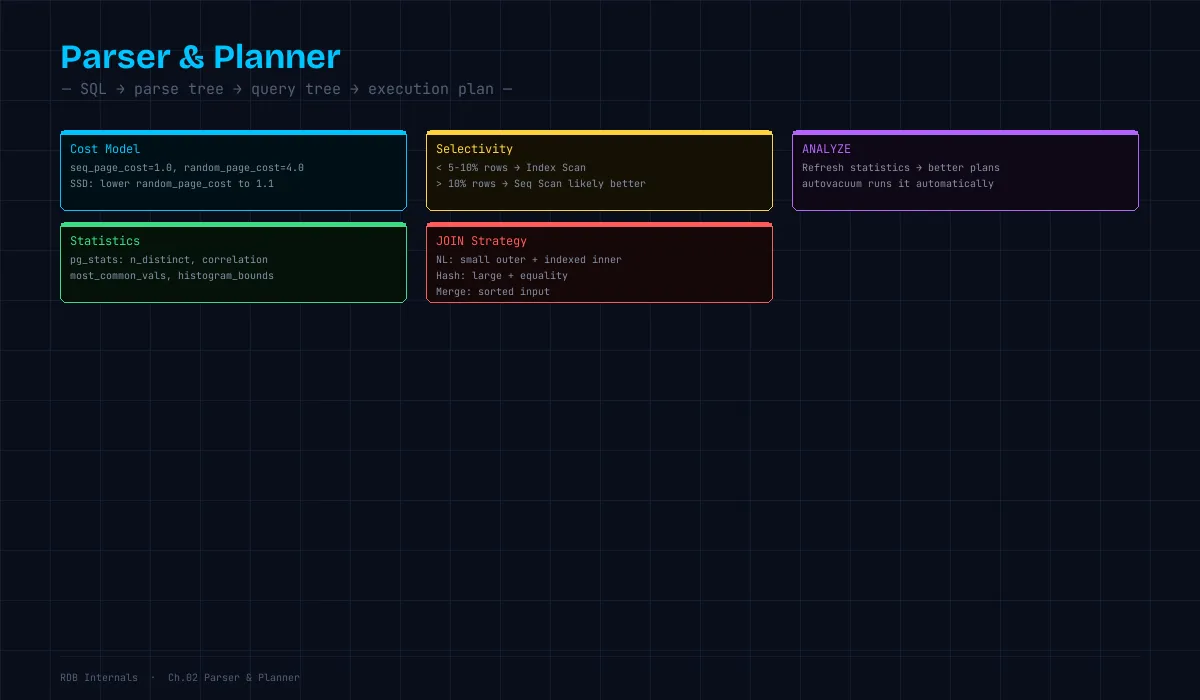
コストモデル
PostgreSQL のプランナーは各操作にコストを割り当てる。
主要なコスト定数(postgresql.conf):
seq_page_cost = 1.0 # シーケンシャルページ読み込み(基準)
random_page_cost = 4.0 # ランダムページ読み込み(シーケンシャルの4倍)
cpu_tuple_cost = 0.01 # 1タプルの処理コスト
cpu_index_tuple_cost = 0.005 # インデックスタプルの処理コスト
cpu_operator_cost = 0.0025 # 演算子の適用コスト
SSD の場合: random_page_cost を 1.1〜1.5 に下げるのが推奨
(SSD はランダムアクセスが HDD ほど遅くない)統計情報:プランナーの判断材料
プランナーはテーブルの統計情報を使ってコストを推定する。
-- 統計情報の確認
SELECT
relname,
reltuples AS estimated_rows,
relpages AS pages_on_disk
FROM pg_class
WHERE relname = 'users';
-- カラムの統計情報
SELECT
attname,
n_distinct, -- ユニーク値の推定数
most_common_vals, -- 最頻出値
most_common_freqs, -- 最頻出値の出現頻度
correlation -- 物理的な並び順との相関(1.0 に近いほど良い)
FROM pg_stats
WHERE tablename = 'users' AND attname = 'status';ANALYZE コマンドが統計情報を更新する。統計情報が古いとプランナーが誤った計画を選ぶ。
ANALYZE users; -- users テーブルの統計情報を更新実行計画の選択例
SELECT * FROM users WHERE age = 25;プランナーが検討する候補:
候補1: Seq Scan(全件スキャン)
コスト = ページ数 × seq_page_cost + 行数 × cpu_tuple_cost
例: 10000ページ × 1.0 + 1000000行 × 0.01 = 20000
候補2: Index Scan(age にインデックスがある場合)
コスト = インデックスページ読み込み + データページランダム読み込み + CPU
例: log(1000000) × random_page_cost + 100行 × random_page_cost + ...
= 24 + 400 + ... ≈ 500
→ 候補2の方がコストが低い → Index Scan を選択選択率(Selectivity)がプランナーの判断を左右する
-- 選択率が低い(結果が少ない)→ インデックスが有利
SELECT * FROM users WHERE id = 12345;
-- 選択率 ≈ 1/1000000 = 0.0001%
-- 選択率が高い(結果が多い)→ Seq Scan が有利
SELECT * FROM users WHERE status = 'active';
-- もし 80% が active なら、インデックスで 80万行をランダムアクセスするより
-- Seq Scan で全件読んだ方が速い経験則:テーブルの 5〜10% 以上の行を返すクエリでは、Seq Scan の方が速いことが多い。
JOIN の実行戦略
SELECT u.name, o.total
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.country = 'JP';Nested Loop Join
for each row in users (外側):
for each row in orders (内側):
if users.id == orders.user_id:
output(row)
計算量: O(N × M)
向いている: 外側テーブルが小さい場合(内側はインデックスで高速化可能)Hash Join
1. 小さい方のテーブル(users)でハッシュテーブルを構築
hash_table[user_id] = user_row
2. 大きい方のテーブル(orders)を走査
for each order:
user = hash_table[order.user_id]
output(user, order)
計算量: O(N + M)
向いている: 両テーブルが大きく、等価条件の JOIN
メモリ: ハッシュテーブルが work_mem に収まる必要があるMerge Join
1. 両テーブルを JOIN キーでソート
2. 2つのポインタを同時に進めながらマッチング
計算量: O(N log N + M log M)(ソート込み)
向いている: 両テーブルが大きく、既にソート済み(インデックスの順序)JOIN 戦略の選択基準
| 戦略 | 向いているケース |
|---|---|
| Nested Loop | 外側が小さい + 内側にインデックス |
| Hash Join | 両テーブルが大きい + 等価条件 |
| Merge Join | 両テーブルがソート済み + 大規模 |
PostgreSQL でプランナーの動作を確認する
-- 実行計画の表示
EXPLAIN SELECT * FROM users WHERE age = 25;
-- 結果例:
-- Index Scan using idx_users_age on users (cost=0.43..8.45 rows=1 width=64)
-- Index Cond: (age = 25)
-- cost=0.43..8.45:
-- 0.43 = 最初の行を返すまでのコスト(startup cost)
-- 8.45 = 全行を返すまでのコスト(total cost)
-- rows=1: 推定される返却行数
-- width=64: 1行あたりの推定バイト数-- JOIN の実行計画
EXPLAIN SELECT u.name, o.total
FROM users u JOIN orders o ON u.id = o.user_id
WHERE u.country = 'JP';
-- 結果例:
-- Hash Join (cost=125.00..1234.56 rows=500 width=40)
-- Hash Cond: (o.user_id = u.id)
-- -> Seq Scan on orders o (cost=0.00..800.00 rows=50000 width=12)
-- -> Hash (cost=100.00..100.00 rows=1000 width=32)
-- -> Seq Scan on users u (cost=0.00..100.00 rows=1000 width=32)
-- Filter: (country = 'JP'::text)プランナーが「間違える」ケース
1. 統計情報が古い
→ ANALYZE を定期実行(autovacuum が自動で行うが、大量 INSERT 直後は手動で)
2. 相関のあるカラムの組み合わせ
→ WHERE city = 'Tokyo' AND country = 'JP' の行数を過小評価
→ 独立と仮定して 0.01 × 0.01 = 0.0001 と推定するが、
実際は Tokyo なら必ず JP(相関が 1.0)
→ PostgreSQL 10+ の拡張統計で対応可能
3. パラメータ化クエリの汎用計画
→ プリペアドステートメントで generic plan が選ばれると、
パラメータの値に関わらず同じ計画が使われる-- 拡張統計の作成(相関カラム用)
CREATE STATISTICS stats_city_country (dependencies)
ON city, country FROM users;
ANALYZE users;まとめ
| フェーズ | 入力 | 出力 | 主な処理 |
|---|---|---|---|
| パーサー | SQL テキスト | 構文木 | 構文チェック |
| アナライザー | 構文木 | クエリツリー | 型チェック、テーブル検証 |
| リライター | クエリツリー | 書き換え済みツリー | ビュー展開、ルール適用 |
| プランナー | クエリツリー | 実行計画 | コスト推定、最適計画選択 |
プランナーの「コスト推定」の品質が RDB のパフォーマンスを大きく左右する。統計情報を新鮮に保つことが、最も基本的なチューニングだ。