事前学習と転移学習 ── GPT・BERT の訓練戦略
LLM との関係:「なぜ LLM はあらゆるタスクをこなせるか」の答えが事前学習と転移学習にある。
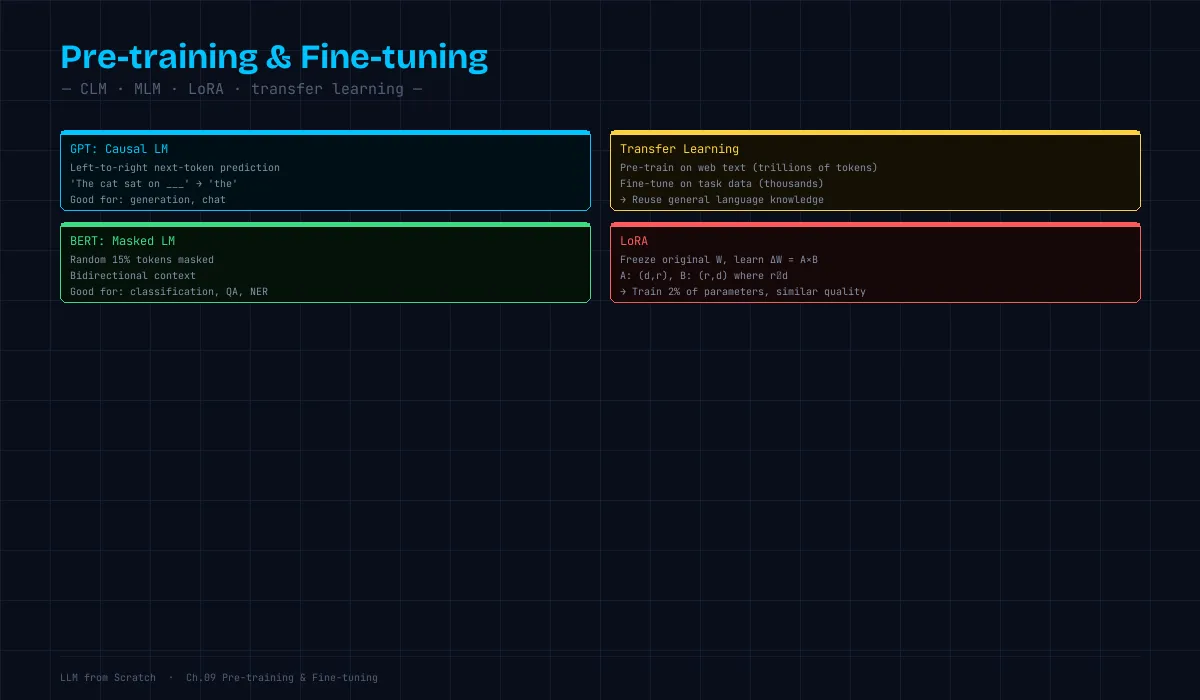
この章で何ができるようになるか:GPT(自己回帰)と BERT(マスク言語モデル)の訓練戦略の違いを説明でき、「事前学習 → ファインチューニング」のパラダイムを理解できる。
自己教師あり学習:ラベルなしデータから学ぶ
LLM の訓練データにはラベルがない。ウェブ上のテキストをそのまま使う。
従来の機械学習(教師あり):
入力: 「この映画は素晴らしい」 ラベル: positive ← 人手でラベル付け
→ ラベル付きデータの作成コストが膨大
自己教師あり学習(LLM):
入力: 「東京は日本の___」 ラベル: 「首都」← テキスト自体から自動生成
→ ウェブ上の数兆トークンのテキストがそのまま訓練データ
→ 人手のラベル付け不要GPT の訓練:Causal Language Modeling(CLM)
「左から右に、次のトークンを予測する」。
入力テキスト: "The cat sat on the mat"
訓練データ(自動生成):
入力: "The" → 正解: "cat"
入力: "The cat" → 正解: "sat"
入力: "The cat sat" → 正解: "on"
入力: "The cat sat on" → 正解: "the"
入力: "The cat sat on the" → 正解: "mat"import torch
import torch.nn as nn
def compute_clm_loss(model, token_ids):
"""
Causal Language Modeling の損失計算
token_ids: (batch_size, seq_len)
"""
# 入力: 最後のトークン以外
input_ids = token_ids[:, :-1]
# ターゲット: 最初のトークン以外(1つずらし)
target_ids = token_ids[:, 1:]
logits = model(input_ids) # (batch, seq_len-1, vocab_size)
# 交差エントロピー損失
loss = nn.CrossEntropyLoss()(
logits.reshape(-1, logits.size(-1)),
target_ids.reshape(-1)
)
return lossGPT の強み:テキスト生成に直接使える(訓練と推論のタスクが一致)。
GPT の弱み:左から右にしか見えない(文脈の右側を参照できない)。
BERT の訓練:Masked Language Modeling(MLM)
「ランダムにマスクしたトークンを予測する」。双方向の文脈を使える。
入力テキスト: "The cat sat on the mat"
15% のトークンをランダムにマスク:
入力: "The [MASK] sat on the mat" → 正解: "cat"
入力: "The cat sat [MASK] the mat" → 正解: "on"
マスク戦略(BERT の工夫):
80%: [MASK] に置換
10%: ランダムなトークンに置換
10%: そのまま(何も変えない)def create_mlm_data(token_ids, mask_prob=0.15, vocab_size=30000):
"""MLM 用の訓練データを作成"""
labels = token_ids.clone()
mask = torch.bernoulli(torch.full(token_ids.shape, mask_prob)).bool()
# マスクされないトークンのラベルは -100(損失計算で無視)
labels[~mask] = -100
# 80% を [MASK] に
mask_token_id = 103 # [MASK] のトークンID
indices_replaced = torch.bernoulli(torch.full(token_ids.shape, 0.8)).bool() & mask
token_ids[indices_replaced] = mask_token_id
# 10% をランダムなトークンに
indices_random = torch.bernoulli(torch.full(token_ids.shape, 0.5)).bool() & mask & ~indices_replaced
random_words = torch.randint(vocab_size, token_ids.shape)
token_ids[indices_random] = random_words[indices_random]
# 残り 10% はそのまま
return token_ids, labelsBERT の強み:双方向の文脈を利用できる → 文の理解タスク(分類・Q&A)に強い。
BERT の弱み:テキスト生成には直接使えない(マスク予測 ≠ 逐次生成)。
GPT vs BERT の使い分け
| GPT(デコーダ型) | BERT(エンコーダ型) | |
|---|---|---|
| 訓練タスク | 次トークン予測(CLM) | マスクトークン予測(MLM) |
| 文脈 | 左のみ(因果マスク) | 双方向 |
| 得意タスク | テキスト生成、チャット | 分類、Q&A、NER |
| 推論方法 | 自己回帰(1トークンずつ) | 並列(全トークン一度に) |
| 代表モデル | GPT-4, Claude, LLaMA | BERT, RoBERTa, DeBERTa |
現在の主流は GPT 型(デコーダ型)。「テキスト生成」が最も汎用的なインターフェースであり、分類・Q&A も「テキストとして生成する」ことで解ける。
訓練データ
GPT-3 の訓練データ(2020年時点):
Common Crawl(フィルタ済み): 410B tokens (60%)
WebText2: 19B tokens (22%)
Books1 + Books2: 12B tokens (8%)
Wikipedia: 3B tokens (3%)
合計: 約 300B tokens
LLaMA 3 の訓練データ(2024年時点):
約 15T tokens(GPT-3 の 50倍)
多言語対応、コード、数学データを含む
重要な前処理:
- 重複排除(同じ文書を何度も学習しない)
- 品質フィルタリング(低品質なページを除去)
- 個人情報の除去
- 有害コンテンツのフィルタリング転移学習:事前学習の知識を活用する
パラダイム:
1. 事前学習(Pre-training): 大量の一般テキストで「言語の知識」を学ぶ
2. ファインチューニング: 特定タスクのデータで微調整
事前学習で獲得される能力:
- 文法の理解
- 意味の理解
- 世界知識(事実情報)
- 推論パターン
- コードの構造
ファインチューニングで付与される能力:
- 特定ドメインの専門知識
- 特定フォーマットの出力
- 指示に従う能力(Instruction Tuning)LoRA:効率的なファインチューニング
class LoRALayer(nn.Module):
"""Low-Rank Adaptation: 元の重みを凍結し、差分だけ学習"""
def __init__(self, original_layer: nn.Linear, rank: int = 8, alpha: float = 16):
super().__init__()
self.original = original_layer
self.original.weight.requires_grad = False # 元の重みは凍結
d_in = original_layer.in_features
d_out = original_layer.out_features
# 低ランクの差分行列 ΔW = A × B
self.A = nn.Parameter(torch.randn(d_out, rank) * 0.01)
self.B = nn.Parameter(torch.zeros(rank, d_in))
self.scaling = alpha / rank
def forward(self, x):
# 元の出力 + 低ランクの差分
return self.original(x) + (x @ self.B.T @ self.A.T) * self.scaling
# 元の重み: 768×768 = 589,824 パラメータ(凍結)
# LoRA: 768×8 + 8×768 = 12,288 パラメータ(学習)
# → 全パラメータの 2% だけ更新(メモリ・計算コスト大幅削減)まとめ
| フェーズ | 内容 | データ量 | コスト |
|---|---|---|---|
| 事前学習 | 一般的な言語能力を獲得 | 数兆トークン | 数百万〜数千万ドル |
| Instruction Tuning | 指示に従う能力を付与 | 数万〜数十万サンプル | 数千〜数万ドル |
| LoRA ファインチューニング | 特定ドメインに特化 | 数千〜数万サンプル | 数百ドル |
| RLHF | 人間の好みに合わせる | 数万の人間評価 | 数十万ドル |
次章では、「モデルを大きくすると何が起きるか」──スケーリング則と訓練インフラの話に進む。