Attention と Transformer ── 「全てを変えた」アーキテクチャ
LLM との関係:GPT、Claude、Gemini──現在の全ての LLM は Transformer ベース。この章がシリーズの核心。
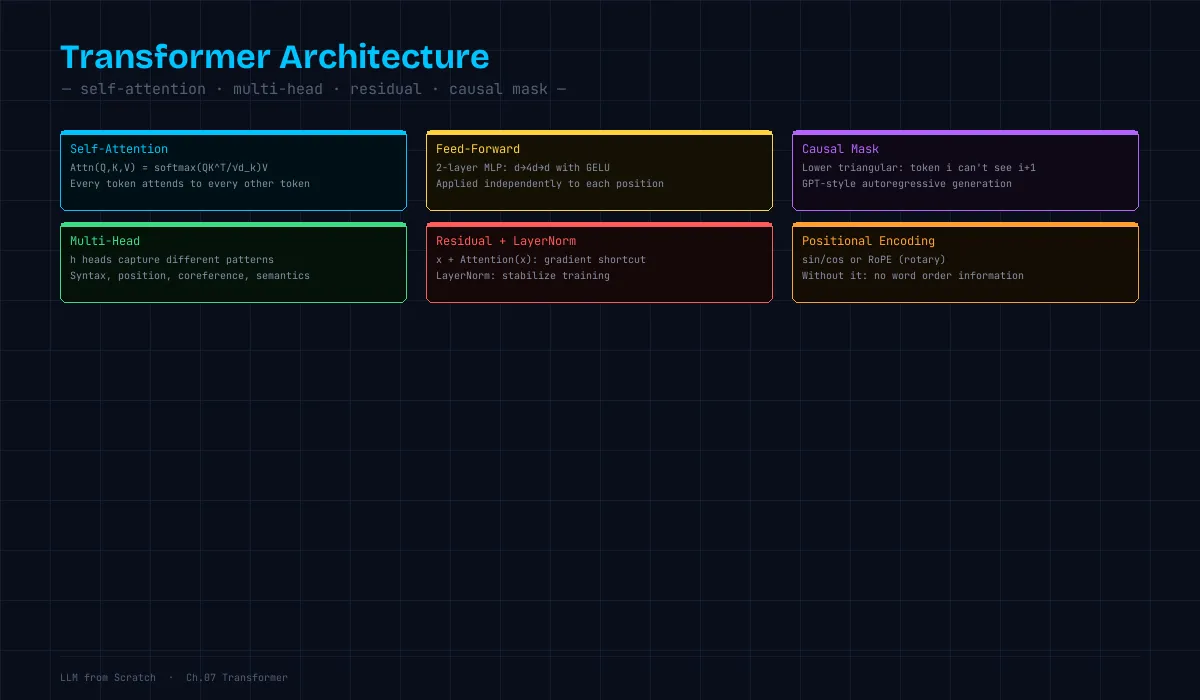
この章で何ができるようになるか:Self-Attention の内部動作を数式・コードで理解し、Transformer ブロックの全体像を説明できるようになる。
Attention の直感
「The cat sat on the mat because it was tired」
「it」は何を指している?人間は即座に「cat」だとわかる。この「参照先を見つける」操作が Attention だ。
"it" は全トークンに「質問」する:
"The" → あまり関連しない → 低い注目
"cat" → 強く関連する → 高い注目 ★
"sat" → やや関連する → 中程度の注目
"on" → 関連しない → 低い注目
"the" → 関連しない → 低い注目
"mat" → やや関連する → 中程度の注目
"because" → 関連しない → 低い注目
→ "cat" に最も注目し、その情報を取り込むSelf-Attention の数式
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
3つの行列:
- Q(Query):「何を知りたいか」
- K(Key):「自分が何を提供できるか」
- V(Value):「提供する情報の中身」
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q: (batch, seq_len, d_k) — クエリ
K: (batch, seq_len, d_k) — キー
V: (batch, seq_len, d_v) — バリュー
"""
d_k = Q.size(-1)
# Step 1: Q と K の内積 → 類似度スコア
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# scores: (batch, seq_len, seq_len) — 全トークンペアの類似度
# Step 2: マスク(因果マスク: 未来のトークンを見えなくする)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# Step 3: ソフトマックスで正規化 → Attention 重み
attention_weights = F.softmax(scores, dim=-1)
# attention_weights: (batch, seq_len, seq_len) — 各トークンが他をどれだけ注目するか
# Step 4: 重みで V を加重平均
output = torch.matmul(attention_weights, V)
# output: (batch, seq_len, d_v)
return output, attention_weightsなぜ $\sqrt{d_k}$ で割るのか
d_k が大きいと、Q と K の内積の値が大きくなる(各要素の積の合計)。
値が大きいと softmax の出力が極端に尖る(ほぼ one-hot に近くなる)。
→ 勾配がほぼ 0 になり、学習が進まない。
√d_k で割ることで内積の分散を 1 に正規化する。Multi-Head Attention
「1つの Attention で全てを捉える」のではなく、複数の Attention ヘッドで異なるパターンを捉える。
class MultiHeadAttention(torch.nn.Module):
def __init__(self, d_model: int, num_heads: int):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.W_q = torch.nn.Linear(d_model, d_model)
self.W_k = torch.nn.Linear(d_model, d_model)
self.W_v = torch.nn.Linear(d_model, d_model)
self.W_o = torch.nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, d_model = x.size()
# 線形変換で Q, K, V を生成
Q = self.W_q(x) # (batch, seq, d_model)
K = self.W_k(x)
V = self.W_v(x)
# ヘッドに分割: (batch, seq, d_model) → (batch, heads, seq, d_k)
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 各ヘッドで Attention を計算
attn_output, _ = scaled_dot_product_attention(Q, K, V, mask)
# ヘッドを結合: (batch, heads, seq, d_k) → (batch, seq, d_model)
attn_output = attn_output.transpose(1, 2).contiguous().view(
batch_size, seq_len, d_model
)
# 最終線形変換
return self.W_o(attn_output)各ヘッドの役割(経験的に発見されたパターン):
ヘッド1: 構文的な依存関係(主語-述語)
ヘッド2: 位置的な近さ(隣のトークンに注目)
ヘッド3: 照応解析(代名詞の参照先)
ヘッド4: 長距離の意味的関連
...
各ヘッドが異なる「見方」を学習するTransformer ブロックの全体像
class TransformerBlock(torch.nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
# Multi-Head Attention
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = torch.nn.LayerNorm(d_model)
# Feed-Forward Network
self.ffn = torch.nn.Sequential(
torch.nn.Linear(d_model, d_ff), # 拡大(d_model → 4×d_model が典型)
torch.nn.GELU(),
torch.nn.Linear(d_ff, d_model), # 元に戻す
)
self.norm2 = torch.nn.LayerNorm(d_model)
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x, mask=None):
# Sub-layer 1: Multi-Head Attention + Residual + LayerNorm
attn_output = self.attention(x, mask)
x = self.norm1(x + self.dropout(attn_output)) # 残差接続
# Sub-layer 2: Feed-Forward + Residual + LayerNorm
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output)) # 残差接続
return x残差接続(Residual Connection)がなぜ重要か
残差接続なし: x → f(x) → g(f(x)) → h(g(f(x)))
→ 96層通すと情報が変容しすぎる
→ 勾配も96層分の積になり消失する
残差接続あり: x → x + f(x) → x + f(x) + g(x + f(x)) → ...
→ 入力 x が直接最終層に「ショートカット」で届く
→ 勾配も直接届く(+1 の項があるため)
→ 層を深くしても学習が安定する位置エンコーディング
Attention は「全トークンを同時に見る」ため、語順の情報がない。位置エンコーディングで補う。
class PositionalEncoding(torch.nn.Module):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(
torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term) # 偶数次元: sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数次元: cos
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
# x: (batch, seq_len, d_model)
return x + self.pe[:, :x.size(1)]RoPE(Rotary Position Embedding):GPT-NeoX、LLaMA で使用。位置情報をベクトルの回転として表現。相対位置の関係が内積に自然に反映される。
因果マスク(Causal Mask):未来を見えなくする
GPT のようなデコーダ型モデルでは、トークン i を予測するとき、i+1 以降のトークンを見てはいけない。
def create_causal_mask(seq_len):
"""下三角行列: 過去のトークンのみ見える"""
mask = torch.tril(torch.ones(seq_len, seq_len))
return mask
# [[1, 0, 0, 0],
# [1, 1, 0, 0],
# [1, 1, 1, 0],
# [1, 1, 1, 1]]
# → トークン3 はトークン0,1,2,3 を見える。トークン4以降は見えない。GPT の全体像
class GPT(torch.nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, d_ff, max_len):
super().__init__()
self.token_embedding = torch.nn.Embedding(vocab_size, d_model)
self.position_encoding = PositionalEncoding(d_model, max_len)
self.blocks = torch.nn.ModuleList([
TransformerBlock(d_model, num_heads, d_ff)
for _ in range(num_layers)
])
self.ln_final = torch.nn.LayerNorm(d_model)
self.lm_head = torch.nn.Linear(d_model, vocab_size, bias=False)
def forward(self, token_ids):
seq_len = token_ids.size(1)
mask = create_causal_mask(seq_len).to(token_ids.device)
x = self.token_embedding(token_ids)
x = self.position_encoding(x)
for block in self.blocks:
x = block(x, mask)
x = self.ln_final(x)
logits = self.lm_head(x) # (batch, seq_len, vocab_size)
return logits
# GPT-3 の規模感:
# vocab_size=50257, d_model=12288, num_heads=96, num_layers=96, d_ff=49152
# パラメータ数 ≈ 175B(1750億)まとめ
| コンポーネント | 役割 | 計算量 |
|---|---|---|
| Self-Attention | 全トークン間の関係を計算 | O(n² × d) |
| Multi-Head | 異なるパターンを並列に捉える | O(n² × d)(ヘッド数で分割) |
| FFN | 非線形変換(表現の変換) | O(n × d × d_ff) |
| 残差接続 | 勾配の安定化 | +(加算のみ) |
| LayerNorm | 出力の正規化 | O(n × d) |
| 位置エンコーディング | 語順情報の付与 | +(加算のみ) |
| 因果マスク | 未来のトークンを遮断 | O(n²) |
次章では、「単語」ではなく「サブワード」に分割するトークナイゼーションを見ていく。