プロローグ ── 「次の単語を予測する」がなぜ知性に見えるのか
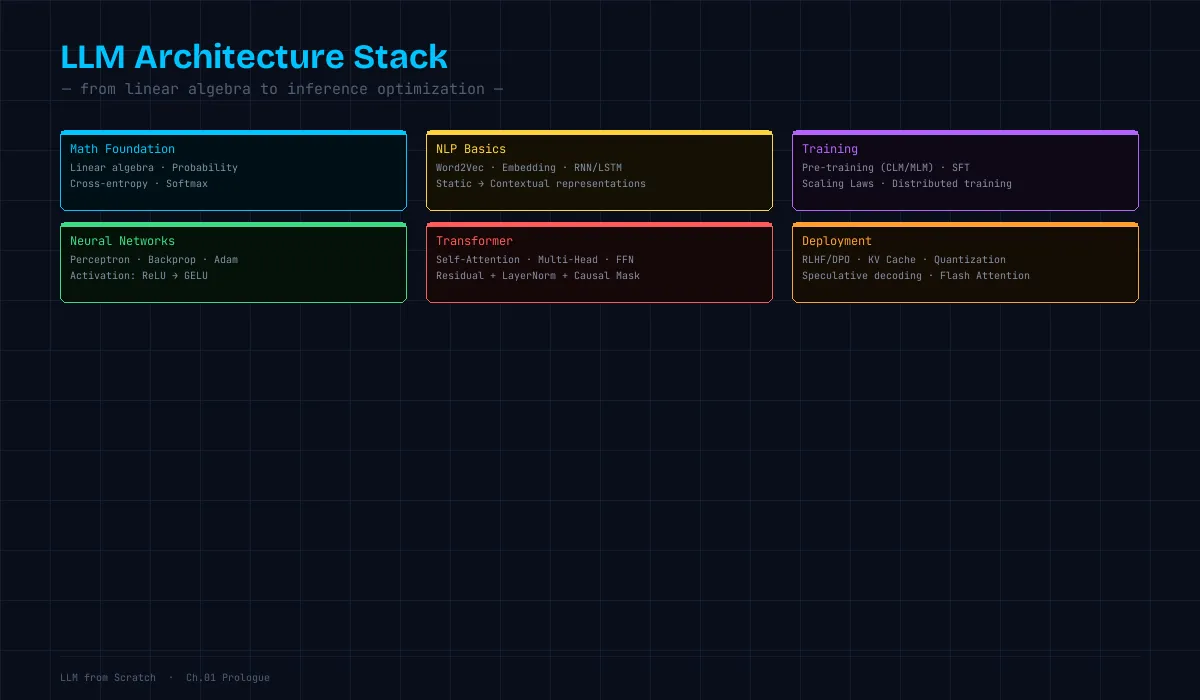
シリーズ構成(全13章)
Part 1 — 数学的基礎 Ch.1 プロローグ(本章) / Ch.2 線形代数 — ベクトル・行列・テンソル / Ch.3 確率と情報理論 — エントロピー・交差エントロピー・ソフトマックス
Part 2 — ニューラルネットワークの基礎 Ch.4 ニューラルネットワーク入門 — パーセプトロンから誤差逆伝播まで / Ch.5 単語の数値化 — 分布仮説と Word2Vec / Ch.6 系列モデルの進化 — RNN・LSTM とその限界
Part 3 — Transformer と LLM Ch.7 Attention と Transformer — 「全てを変えた」アーキテクチャ / Ch.8 トークナイゼーション — BPE・SentencePiece / Ch.9 事前学習と転移学習 — GPT・BERT の訓練戦略
Part 4 — スケーリングと実用化 Ch.10 スケーリング則と訓練インフラ — Chinchilla・分散訓練 / Ch.11 RLHF とアラインメント — 「役に立つAI」への調整 / Ch.12 推論の高速化 — KV Cache・量子化・投機的デコーディング / Ch.13 エピローグ
この記事で何を扱うか
ChatGPT に「東京タワーの高さは?」と聞くと「333メートルです」と返ってくる。この応答は「知識の検索」のように見える。しかし LLM の内部で起きていることは根本的に違う。
LLM がやっていることを一言で言うと:
「これまでの文脈が与えられたとき、次に来る確率が最も高い単語(トークン)を予測する」
入力: "東京タワーの高さは"
モデルの出力(確率分布):
"333" → 0.85
"332" → 0.03
"約" → 0.02
"高い" → 0.01
...この「次の単語を当てる」という単純なタスクを、巨大なデータと巨大なモデルで極めると、翻訳・要約・推論・コード生成──あらゆる言語能力が「副産物として」立ち現れる。これが LLM の本質であり、驚きの源泉だ。
対象読者
対象:ソフトウェアエンジニア(ML 専門でなくてもよい)
「LLM を API として使っているが、中身は知らない」という方
「Transformer とは何か」を理論から理解したい方
難易度:★★★★☆
読了時間:約5時間(全章通読時)
前提知識:高校数学(行列の基礎)、Python が読めるなぜエンジニアが LLM の内部を知るべきか
1. プロンプトエンジニアリングの精度が上がる
→ トークナイゼーション(Ch.8)を理解すると、
なぜ「JSON を出力して」より「以下のJSON形式で出力して: {...}」が
効果的かが腹落ちする
2. コスト・レイテンシの最適化
→ KV Cache(Ch.12)を理解すると、
なぜ長い System Prompt がコストに直結するかがわかる
3. LLM の限界を正しく認識できる
→ 「次の単語を予測する」仕組みを知ると、
なぜ LLM がハルシネーションを起こすかが自明になる
4. 新しい技術の評価ができる
→ 「RAG」「LoRA」「量子化」──流行語を正しく評価するには
基盤の理解が必要LLM を理解するために必要な CS 基礎
このシリーズは以下の知識を「下から積み上げる」構成になっている。
Level 1: 線形代数
ベクトル・行列の演算 → テンソル → GPU が得意な理由
Level 2: 確率・情報理論
確率分布 → 交差エントロピー損失 → ソフトマックス関数
Level 3: ニューラルネットワーク
パーセプトロン → 多層NN → 誤差逆伝播 → 勾配降下法
Level 4: 自然言語処理の基礎
単語の数値化(Word2Vec)→ 系列モデル(RNN/LSTM)
Level 5: Transformer
Self-Attention → Multi-Head Attention → 位置エンコーディング
Level 6: LLM の訓練と運用
事前学習 → ファインチューニング → RLHF → 推論最適化各レベルは前のレベルの上に立っている。「なぜ Attention が必要か」は「RNN の何が問題か」を知らないと理解できない。「RNN の問題」は「系列データをどう扱うか」を知らないとわからない。だから下から積み上げる。
「次の単語予測」の威力
「次の単語を予測するだけ」がなぜこれほど強力なのか。直感的に理解するための思考実験:
もし、あらゆる文章の「次の単語」を完璧に予測できるなら:
「The capital of France is ___」→ "Paris"
→ 事実知識を持っている
「He felt sad because ___」→ "his friend moved away"
→ 因果関係を理解している
「def fibonacci(n):\n if n <= 1:\n return ___」→ "n"
→ プログラミングの構造を理解している
「この文を英語に翻訳すると ___」→ 翻訳ができる
「以下の文章を要約すると ___」→ 要約ができる「次の単語を正しく予測する」ことは、言語の構造・知識・論理・慣習を暗黙的に学習することを意味する。Ilya Sutskever(OpenAI 共同創設者)の言葉を借りれば、「十分に良い次単語予測は、知能と区別がつかない」。
シリーズを通した読み方
各章は以下の構造で書いている。
1. なぜこの知識が必要か(LLM のどの部分に関わるか)
2. 概念の直感的な説明
3. 数式とコードによる実装
4. 「次の章への橋渡し」数式が出てくるが、全て Python コードに対応させている。「数式だけ」で終わらず、「動くコード」で確認できるようにした。
では、最も基礎的な土台──線形代数──から始めよう。