系列モデルの進化 ── RNN・LSTM とその限界
LLM との関係:RNN/LSTM は Transformer の「前の世代」の系列モデル。なぜ Transformer に置き換えられたかを理解することで、Attention の価値が明確になる。
この章で何ができるようになるか:RNN の「記憶の仕組み」と「長距離依存の限界」を説明でき、LSTM のゲート機構がその限界をどう緩和したかを理解できる。
RNN(Recurrent Neural Network)
系列データ(テキスト・音声・時系列)を「1トークンずつ順番に」処理し、隠れ状態(hidden state)に「これまでの情報」を蓄積する。
class SimpleRNN:
def __init__(self, input_dim, hidden_dim, output_dim):
self.Wxh = np.random.randn(hidden_dim, input_dim) * 0.01
self.Whh = np.random.randn(hidden_dim, hidden_dim) * 0.01
self.Why = np.random.randn(output_dim, hidden_dim) * 0.01
self.bh = np.zeros(hidden_dim)
self.by = np.zeros(output_dim)
def forward(self, inputs):
"""
inputs: トークン埋め込みの列 [(embed_dim,), ...]
各タイムステップで hidden state を更新
"""
h = np.zeros(self.Whh.shape[0]) # 初期隠れ状態
outputs = []
for x in inputs:
# 隠れ状態の更新: h_t = tanh(W_xh × x_t + W_hh × h_{t-1} + b)
h = np.tanh(self.Wxh @ x + self.Whh @ h + self.bh)
# 出力: y_t = W_hy × h_t + b
y = self.Why @ h + self.by
outputs.append(y)
return outputs, h x₁ x₂ x₃ x₄
↓ ↓ ↓ ↓
h₀ → [RNN] → [RNN] → [RNN] → [RNN] → h₄
↓ ↓ ↓ ↓
y₁ y₂ y₃ y₄
各タイムステップで同じ重み(Wxh, Whh, Why)を共有
→ パラメータ効率が良い
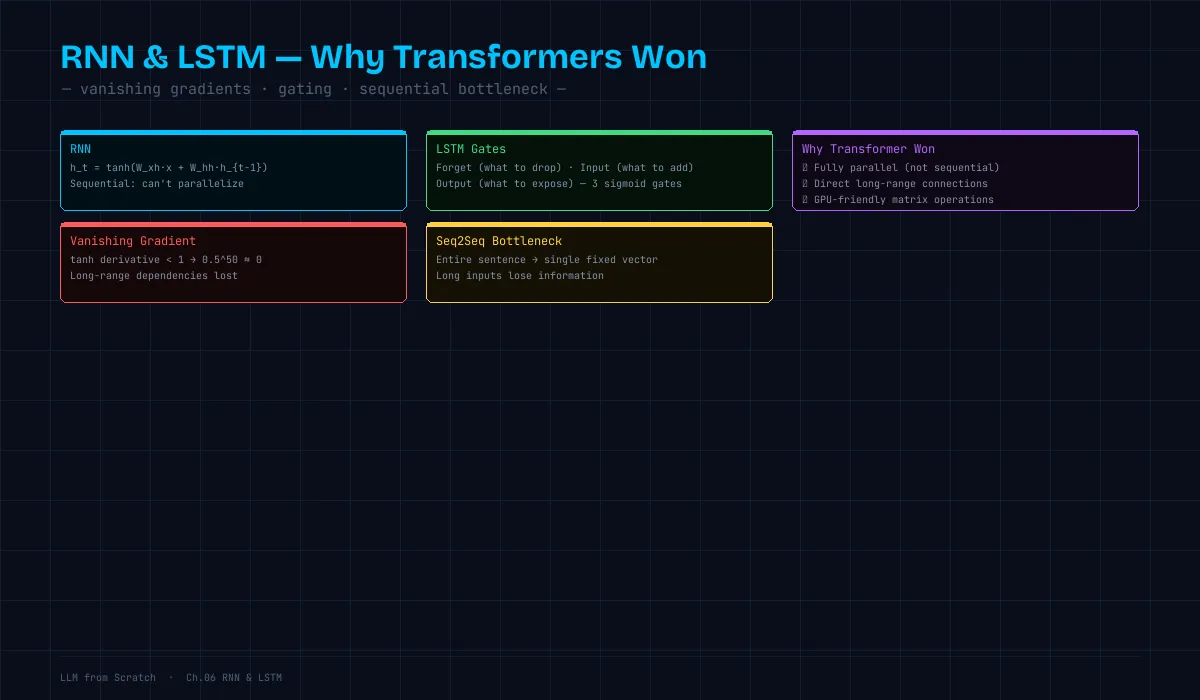
→ 任意の長さの系列を処理できるRNN の致命的な問題:勾配消失
「私は 東京で 生まれた 日本語を 話す 子供と 一緒に 住んでいる エンジニア です」
「です」を予測するとき、「私は」の情報が必要。
しかし RNN では「私は」→「です」の間に 9 ステップある。
逆伝播で 9 回 tanh の微分を掛け合わせると:
tanh の微分は最大 1.0、ほぼ 0〜0.5 の範囲
→ 0.5^9 ≈ 0.002 → 勾配がほぼ消える
→ 「私は」に対する重みの更新がほぼ起きない
→ 長距離の依存関係を学習できないLSTM(Long Short-Term Memory)
1997年に Hochreiter & Schmidhuber が発明。3つのゲートで「何を覚え、何を忘れるか」を制御する。
class LSTM:
def forward_step(self, x_t, h_prev, c_prev):
"""
x_t: 現在の入力
h_prev: 前の隠れ状態
c_prev: 前のセル状態(長期記憶)
"""
# 入力を結合
combined = np.concatenate([h_prev, x_t])
# 忘却ゲート: 過去の記憶のどの部分を保持するか
f_t = sigmoid(self.Wf @ combined + self.bf) # 0〜1
# 入力ゲート: 新しい情報のどの部分を記憶するか
i_t = sigmoid(self.Wi @ combined + self.bi) # 0〜1
# 候補セル: 新しい記憶の候補
c_candidate = np.tanh(self.Wc @ combined + self.bc) # -1〜1
# セル状態の更新: 忘れるべきを忘れ、覚えるべきを覚える
c_t = f_t * c_prev + i_t * c_candidate
# 出力ゲート: セル状態のどの部分を出力するか
o_t = sigmoid(self.Wo @ combined + self.bo) # 0〜1
h_t = o_t * np.tanh(c_t)
return h_t, c_t 忘却ゲート(f) 入力ゲート(i)
↓ ↓
c_{t-1} → [× forget] → [+ new memory] → c_t(長期記憶)
↓
[× 出力ゲート(o)]
↓
h_t(短期記憶/出力)なぜ勾配消失を緩和できるか:セル状態 c_t は忘却ゲートで掛け算ではなく選択的な保持を行う。忘却ゲートが 1 に近ければ、勾配がほぼそのまま遠い過去に伝わる。
RNN/LSTM の限界:なぜ Transformer に負けたか
限界1:逐次処理しかできない
RNN/LSTM:
トークン1 → 処理 → トークン2 → 処理 → トークン3 → 処理
→ 各ステップが前のステップに依存 → 並列化できない
→ GPU の数千コアのうち、1コアしか使えない
Transformer:
[トークン1, トークン2, トークン3] → 全トークンを同時に処理
→ 行列演算として並列化 → GPU をフル活用限界2:長距離依存の実質的な制限
LSTM は理論上は長距離依存を学習できるが、実用上は 100〜200 トークン程度が限界。
LSTM: トークン1の情報がトークン100に届くには、99個のゲートを通過する
→ 情報が「薄まる」
Transformer: トークン1とトークン100が Attention で直接接続される
→ 情報の劣化なし限界3:ボトルネック問題(Seq2Seq)
翻訳モデル(Encoder-Decoder RNN)では、入力文全体を1つの固定長ベクトルに圧縮する。
Encoder: 「今日は天気が良いですね」→ [h1, h2, ..., h9] → h9(最終隠れ状態)
Decoder: h9 → 「It's a nice day today」
問題: h9 という1つのベクトルに文の全情報を詰め込む必要がある
→ 長い文ほど情報が失われる(ボトルネック)
→ これを解決するために Attention が発明された(Bahdanau et al., 2014)RNN → Attention → Transformer の進化
2014: Seq2Seq (Sutskever et al.)
→ Encoder-Decoder RNN で翻訳
→ ボトルネック問題
2015: Attention (Bahdanau et al.)
→ Decoder が Encoder の全タイムステップを「注目」して参照
→ ボトルネック解消
2017: Transformer (Vaswani et al., "Attention Is All You Need")
→ RNN を完全に排除し、Attention のみで構成
→ 並列化可能、長距離依存に強い
→ 現在の全 LLM の基盤まとめ
| モデル | 長距離依存 | 並列化 | 訓練速度 | 代表例 |
|---|---|---|---|---|
| RNN | ❌ 勾配消失 | ❌ 逐次 | 遅い | — |
| LSTM | △ 改善(実質200トークン) | ❌ 逐次 | 遅い | Google 翻訳(〜2016) |
| Transformer | ✅ Attention で直接参照 | ✅ 完全並列 | 高速 | GPT, BERT, Claude |
次章では、RNN の限界を一挙に解決した Attention と Transformer のアーキテクチャを詳しく見ていく。