AgentCore へ移行する ── Runtime / Memory / Identity / Gateway / Observability
対象読者:Bedrock Agents で動くものは作れたが、Memory / Identity / 観測 / マルチフレームワーク対応など本番要件を別レイヤーで解決したい読者 難易度:★★★★☆(実装ハンズオン) 対象バージョン:
@aws-sdk/client-bedrock-agentcorev3 系 /@aws-sdk/client-bedrock-agentcore-controlv3 系(GA 直後のため最新公式 docs を要参照) 想定読了時間:約 60 分 関連章:第 9 章(Bedrock Agents)/ 第 11 章(Guardrails)/ 第 13 章(観測)
マネージドな ReAct で動く、それだけでは足りない理由
前章で helpdesk-ai は、ようやく「単発の応答装置」から「人事 API を叩いて休暇残数を確かめ、申請まで実行する多段ステップのエージェント」へと進化した。Bedrock Agents の Action Groups と Trace でほぼノーコードで動き、社内デモも通った。
ここで足を止めて、次の質問に答えてみてほしい。
- 同時に 30 人が使ったとき、誰のセッションがどれかを取り違えないか
- 田中さんが先週話した経費申請の続きを、今日もう一度自然に再開できるか
- Slack OAuth でログインしたユーザーの「本人性」を、エージェントが扱う社内 API まで引き継げているか
- 応答が劣化し始めたとき、原因の箇所を5 分以内に特定できるか
これらは「PoC が動いた」の延長線上にはない。マネージドな ReAct ループに Production 用のインフラを足さないと埋まらない穴だ。Bedrock Agents は「ReAct を AWS が代わりに回してくれる」サービスであって、本番運用に必要なセッション分離・長期メモリ・外部 ID 連携・観測・ポリシー強制まで面倒を見てくれるわけではない。
2025 年 10 月に GA した AgentCore は、ここを埋めるために用意された別系統のサービスだ1。本章では ch09 で作った Bedrock Agents 版 helpdesk-ai を AgentCore に乗せ替えながら、9 コンポーネントを順に押さえていく。
AgentCore は「Bedrock Agents の上位互換」ではない
最初に誤解を解いておく。AgentCore は Bedrock Agents の v2 ではない。両者は階層が違うサービスだ。
graph TB
subgraph "アプリケーション / フレームワーク層"
BA[Bedrock Agents<br/>マネージドな ReAct]
SA[Strands Agents SDK]
LG[LangGraph]
CA[CrewAI]
Custom[任意の自作エージェント]
end
subgraph "AgentCore(Production 向け共通インフラ)"
RT[Runtime]
MEM[Memory]
ID[Identity]
GW[Gateway]
BR[Browser]
CI[Code Interpreter]
OB[Observability]
PO[Policy]
EV[Evaluations]
end
subgraph "モデル層(フレームワーク非依存)"
Claude[Claude / Nova / Llama / Mistral / ...]
end
BA --> RT
SA --> RT
LG --> RT
CA --> RT
Custom --> RT
RT --> Claude
MEM -.-> RT
ID -.-> RT
GW -.-> RT
BR -.-> RT
CI -.-> RT
OB -.-> RT
PO -.-> RT
EV -.-> RTポイントは 3 つ。
- 別レイヤーのインフラ。Bedrock Agents・Strands Agents SDK・LangGraph・CrewAI、あるいは独自実装のエージェントをすべてこの上に乗せられる
- フレームワーク非依存。Bedrock Agents で動かしていたものを、後から LangGraph に乗せ替えてもインフラは継続して使える
- モデル非依存。Claude / Nova / Llama / Mistral、極論 SageMaker でセルフホストしたモデルでも、同じコンポーネントが効く
AgentCore は「エージェント実装にロックインしない、本番運用のための共通インフラ」だ。Bedrock Agents から AgentCore への移行は「乗り換え」ではなく「下にインフラを敷く」と捉えるのが正しい。
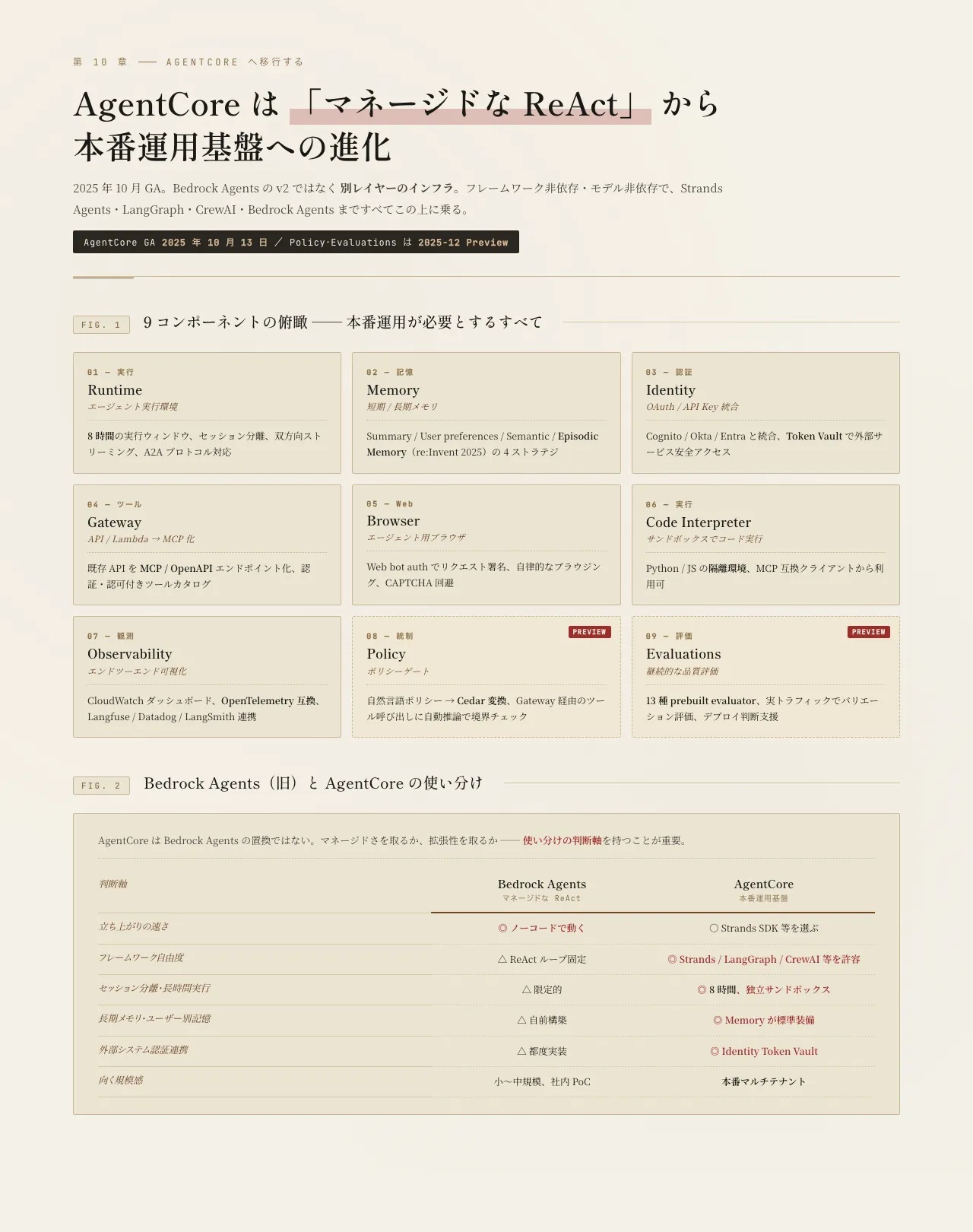
9 コンポーネントを一望する
AgentCore は次の 9 コンポーネントで構成されている。まずはそれぞれが「何を埋めるのか」だけ頭に入れてほしい。詳細は本章の後半と、Part 3 の評価章・観測章で順次掘り下げる。
| コンポーネント | 役割 | 旧 Bedrock Agents で足りなかったこと |
|---|---|---|
| Runtime | エージェント実行環境。最大 8 時間の実行、セッション完全分離、A2A プロトコル | 長時間タスク、テナント間の状態漏洩防止、エージェント間連携 |
| Memory | Session-level の短期記憶+ Cross-session の長期記憶(Summary / User preferences / Semantic / Episodic) | 「先週の続き」を再開する記憶、ユーザー嗜好の蓄積 |
| Identity | Cognito / Okta / Microsoft Entra との統合、Token Vault | 外部 IdP の本人性をエージェント内のツール呼び出しまで伝播 |
| Gateway | 既存の REST API や Lambda を MCP エンドポイントに変換、ツールカタログ、認証 | OpenAPI スキーマを 1 つずつ Action Group に手書きする運用 |
| Browser | Web bot auth で署名されたエージェント用ブラウザ | 「Cloudflare に弾かれるエージェント」「CAPTCHA で止まるエージェント」 |
| Code Interpreter | Python / JS のサンドボックス実行環境 | 計算・データ加工のためにわざわざ Lambda を組む手間 |
| Observability | CloudWatch ダッシュボード、OpenTelemetry の Gen-AI セマンティクス互換 | Trace を JSON で眺める運用、外部 APM への連携 |
| Policy(2025-12 Preview)2 | 自然言語ポリシー → Cedar 変換、自動推論で境界チェック | 「このツールはこの条件下でしか叩かせない」のコード化 |
| Evaluations(2025-12 Preview)2 | 実トラフィックでバリエーション評価、デプロイ判断支援 | プロンプト変更時に「劣化していない」と言い切れない不安 |
料金は本章では扱わない。AgentCore は利用量ベースの課金で、コンポーネントごとに単位が異なる。最新の料金体系は AWS 公式の AgentCore ページで確認すること(コスト設計の全体は ch15 で扱う)。
helpdesk-ai を AgentCore に乗せ替える
ch09 の構成は「ヘルプデスク Bot → Bedrock Agents → Lambda(人事 API) / Knowledge Bases」だった。これを AgentCore に乗せ替えると次のようになる。
flowchart LR
subgraph "Slack / Web UI"
User[社員]
end
subgraph "AgentCore"
Identity[Identity<br/>Slack OAuth → 内部ID]
Runtime[Runtime<br/>セッション分離・8h 実行]
Memory[Memory<br/>個人別履歴<br/>Summary + Semantic]
Gateway[Gateway<br/>人事 API → MCP]
Obs[Observability<br/>OTEL Gen-AI]
end
subgraph "既存リソース"
BA[Bedrock Agents<br/>or Strands Agents]
KB[Knowledge Bases<br/>社内規程]
HR[人事 API / Lambda]
end
User -->|OAuth| Identity
Identity --> Runtime
Runtime <--> Memory
Runtime --> BA
BA --> KB
BA -->|MCP| Gateway
Gateway --> HR
Runtime -.-> Obsch09 から残るのは Bedrock Agents 本体(ReAct ループ部分)・Knowledge Bases・人事 API の Lambda。ロジックには手を入れず、その周りを AgentCore のインフラで包むのが移行の基本姿勢だ。
移行ステップの全体像
flowchart TD
Step1[Step 1<br/>Identity 設定<br/>Slack OAuth → Cognito User Pool]
Step2[Step 2<br/>Gateway 設定<br/>人事 API を MCP 化]
Step3[Step 3<br/>Memory 設定<br/>actor_id ベースで長期記憶]
Step4[Step 4<br/>Runtime へデプロイ<br/>Bedrock Agents をそのまま乗せる]
Step5[Step 5<br/>Observability 有効化<br/>OTEL Gen-AI セマンティクス]
Step6[Step 6<br/>本番運用設定<br/>idle timeout / Guardian Agent]
Step1 --> Step2 --> Step3 --> Step4 --> Step5 --> Step6順に見ていく。
Step 1 : Identity で Slack OAuth を社内 ID に橋渡しする
ch09 までは sessionId を crypto.randomUUID() で生成していた。これでは「同じ田中さんからの 2 回目のリクエスト」を判別できない。本人を識別するのは Identity の仕事だ。
AgentCore Identity は Cognito / Okta / Microsoft Entra などの OIDC / SAML IdP と統合できる。helpdesk-ai では Slack OAuth で認証したユーザーを Cognito User Pool に federate し、sub を actor_id として下流に渡す。
AgentCore のクライアント SDK は
@aws-sdk/client-bedrock-agentcore(データプレーン)と@aws-sdk/client-bedrock-agentcore-control(コントロールプレーン)の 2 パッケージに分かれている。GA から日が浅く、本書では本文の見通しを優先してAgentCoreClientという略称で書くが、最新の クラス名・コマンド名・パッケージ分割は AWS SDK for JavaScript v3 の公式ドキュメントを必ず参照してほしい。
// src/agentcore/identity.ts
import {
AgentCoreClient,
CreateWorkloadIdentityCommand,
} from "@aws-sdk/client-bedrock-agentcore";
const agentcore = new AgentCoreClient({
region: process.env.AWS_REGION ?? "us-east-1",
maxAttempts: 5,
retryMode: "adaptive",
});
// Slack OAuth で発行されたトークンを引き取り、AgentCore に渡す identity
export async function createHelpdeskWorkloadIdentity() {
const res = await agentcore.send(
new CreateWorkloadIdentityCommand({
name: "helpdesk-ai-slack",
// Cognito User Pool を OIDC provider として登録した想定
identityProviderConfig: {
oidc: {
issuer: process.env.COGNITO_ISSUER_URL!, // https://cognito-idp.<region>.amazonaws.com/<pool-id>
clientId: process.env.COGNITO_CLIENT_ID!,
// Slack から渡る claim を Cognito 経由でマッピング
claimMappings: {
actorId: "sub", // helpdesk 内では sub を actor_id として使う
email: "email",
tenantId: "custom:workspace_id", // Slack workspace を tenant 境界に
},
},
},
// Token Vault: API トークンや SaaS 連携の secret を AgentCore に保管
tokenVaultEnabled: true,
}),
);
return res.workloadIdentityId!;
}ポイントは 2 つ。
claimMappingsで Slack のworkspace_idをtenantIdとして明示し、Runtime のセッション分離と Memory のスコープ分けに使うtokenVaultEnabled: trueで Token Vault を有効化。Slack や Google Workspace の API トークンを AgentCore に保管し、エージェントがツール呼び出し時にだけ取り出せる。アプリケーションコードに長期トークンを置かないのが Production の最低ラインだ
Step 2 : Gateway で人事 API を MCP エンドポイントに変える
ch09 では人事 API を Lambda に包み、Bedrock Agents の Action Group として OpenAPI スキーマで定義していた。新しいエージェントフレームワーク(Strands Agents SDK や LangGraph)に乗せ替えるたびに、この定義を書き直すのは骨が折れる。
AgentCore Gateway は、既存の REST API や Lambda を MCP(Model Context Protocol)エンドポイントに変換するファサードだ。一度 Gateway に登録しておけば、Bedrock Agents から見ても、LangGraph から見ても、Strands Agents から見ても、同じツールカタログとして見える。
// src/agentcore/gateway.ts
import {
AgentCoreClient,
CreateGatewayCommand,
CreateGatewayTargetCommand,
} from "@aws-sdk/client-bedrock-agentcore";
const agentcore = new AgentCoreClient({
region: process.env.AWS_REGION ?? "us-east-1",
maxAttempts: 5,
retryMode: "adaptive",
});
export async function setupHelpdeskGateway(workloadIdentityId: string) {
// 1) Gateway 本体を作成
const gw = await agentcore.send(
new CreateGatewayCommand({
name: "helpdesk-gateway",
protocol: "MCP",
// Identity と統合:呼び出し時に actor_id が透過的に伝わる
workloadIdentityId,
}),
);
const gatewayId = gw.gatewayId!;
// 2) 既存の人事 API を MCP ツールとして登録
await agentcore.send(
new CreateGatewayTargetCommand({
gatewayId,
// ❌ 悪い例: name: "getBalance" → どのリソース系のどの操作か不明
// ✅ 良い例: httpVerb__actionGroupName__apiName 形式
name: "get__hr__leave_balance",
description: "指定 employee_id の年次休暇残数を取得",
target: {
lambda: {
functionArn: process.env.HR_LAMBDA_ARN!,
},
},
inputSchema: {
type: "object",
properties: {
employeeId: { type: "string", description: "社員 ID" },
},
required: ["employeeId"],
},
}),
);
await agentcore.send(
new CreateGatewayTargetCommand({
gatewayId,
name: "post__hr__leave_request",
description: "休暇申請を提出",
target: {
lambda: { functionArn: process.env.HR_LAMBDA_ARN! },
},
inputSchema: {
type: "object",
properties: {
employeeId: { type: "string" },
startDate: { type: "string", description: "YYYY-MM-DD" },
endDate: { type: "string", description: "YYYY-MM-DD" },
reason: { type: "string" },
},
required: ["employeeId", "startDate", "endDate"],
},
}),
);
return gatewayId;
}ツール名の httpVerb__actionGroupName__apiName フォーマットは、AWS が AgentCore の本番運用ガイドで推奨している命名規約だ3。get__hr__leave_balance のように 「HTTP メソッド × ドメイン × 操作」が一目で読める形にしておくと、エージェントが「どのツールを呼ぶべきか」を判断するときの精度が上がる。
Step 3 : Memory で「先週の続き」を再開できるようにする
ch09 までの helpdesk-ai は、セッションが切れたら忘れる。「先週、出張交通費 1.2 万円の申請をしました」と田中さんに毎週話してもらうのは現実的ではない。
AgentCore Memory は Session-level(短期) と Cross-session(長期) の 2 層構造を持ち、長期メモリは 4 つのストラテジから選べる4。
| ストラテジ | 何が残るか | helpdesk-ai での使いどころ |
|---|---|---|
| Summary | 会話の自動要約 | 「田中さんと先週話した経費申請の流れ」を 1 段落で残す |
| User preferences | ユーザー固有の嗜好 | 「田中さんは Slack DM での受領通知を好む」 |
| Semantic | 意味検索可能なファクト | 「田中さん = 営業部 = 月次 5 件程度の経費申請」 |
| Episodic5 | 過去の具体的なエピソード | 「2026-05-15 に休暇申請を却下された」 |
helpdesk-ai では Summary と Semantic の 2 つを actor_id ベース(=ユーザーごと)に有効化する。
// src/agentcore/memory.ts
import {
AgentCoreClient,
CreateMemoryCommand,
} from "@aws-sdk/client-bedrock-agentcore";
const agentcore = new AgentCoreClient({
region: process.env.AWS_REGION ?? "us-east-1",
maxAttempts: 5,
retryMode: "adaptive",
});
export async function setupHelpdeskMemory() {
const res = await agentcore.send(
new CreateMemoryCommand({
name: "helpdesk-memory",
// セッション境界は actor_id(=ユーザー)+ session_id
// テナント境界として tenant_id(=Slack workspace)も区切る
scope: {
actorIdSource: "claim:actorId", // Identity の claim を引き継ぐ
tenantIdSource: "claim:tenantId",
},
strategies: [
{
type: "SUMMARY",
// 会話 N ターンごとに要約を自動更新
summaryConfig: { triggerEveryNTurns: 10 },
},
{
type: "SEMANTIC",
// 意味検索のための埋め込みモデル
semanticConfig: {
embeddingModelArn:
"arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-embed-text-v2:0",
},
},
],
// Cross-session の保持期間。コンプライアンス要件に応じて短く
retentionDays: 90,
}),
);
return res.memoryId!;
}ここで重要なのは、actor_id を Identity から自動的に引き継ぐ点だ。アプリケーション側で「今このリクエストは誰のものか」を毎回伝える必要がない。Slack OAuth → Cognito → AgentCore Identity → Memory までが claim ベースで貫通している。これが「セッション分離」の実装的な意味だ。
Step 4 : Runtime にデプロイする
Identity・Gateway・Memory が揃ったら、最後に Runtime にエージェント本体をデプロイする。Bedrock Agents の構成は ch09 のまま残し、Runtime からそれを呼ぶ形にする。
// src/agentcore/runtime-deploy.ts
import {
AgentCoreClient,
CreateAgentRuntimeCommand,
} from "@aws-sdk/client-bedrock-agentcore";
const agentcore = new AgentCoreClient({
region: process.env.AWS_REGION ?? "us-east-1",
maxAttempts: 5,
retryMode: "adaptive",
});
export async function deployHelpdeskRuntime(args: {
workloadIdentityId: string;
memoryId: string;
gatewayId: string;
bedrockAgentId: string;
bedrockAgentAliasId: string;
}) {
const res = await agentcore.send(
new CreateAgentRuntimeCommand({
name: "helpdesk-runtime",
// 既存の Bedrock Agents をそのまま実行ロジックとして採用
// 別案:containerImage で Strands Agents SDK や LangGraph 製コンテナを乗せることも可能
executor: {
bedrockAgent: {
agentId: args.bedrockAgentId,
agentAliasId: args.bedrockAgentAliasId,
},
},
workloadIdentityId: args.workloadIdentityId,
memoryId: args.memoryId,
gatewayId: args.gatewayId,
// タイムアウト:本番は idle 10–15 分、開発・デモは idle 2–5 分が推奨
sessionConfig: {
idleTimeoutSeconds: 600, // 本番想定で 10 分
maxExecutionSeconds: 28800, // 上限 8 時間
},
observabilityConfig: {
otelEnabled: true, // OTEL Gen-AI セマンティクスでトレース出力
},
}),
);
return res.agentRuntimeId!;
}executor に bedrockAgent を指定しているのが、まさに「ロジックには手を入れず、その周りを AgentCore で包む」移行の象徴的な部分だ。あとから「もっと細かい制御が欲しい」と思ったときは、executor を containerImage に切り替えて Strands Agents SDK や LangGraph 製のコンテナを乗せる、という移行パスが残っている。フレームワーク選択の意思決定を、Runtime デプロイ時点で固定しなくていいのが AgentCore の設計思想だ。
Step 5 : クライアントからの呼び出し
クライアント側は ch09 の InvokeAgent から InvokeAgentRuntime に変わる。actor_id と session_id を毎回明示的に渡す点が Bedrock Agents との違いだ。
// src/handlers/agent.ts (ch10 版)
import {
AgentCoreClient,
InvokeAgentRuntimeCommand,
} from "@aws-sdk/client-bedrock-agentcore";
const agentcore = new AgentCoreClient({
region: process.env.AWS_REGION ?? "us-east-1",
maxAttempts: 5,
retryMode: "adaptive",
});
export async function askHelpdesk(input: {
userQuestion: string;
actorId: string; // Slack OAuth から取れる sub
tenantId: string; // Slack workspace_id
sessionId: string; // 同じ会話内では使い回す
oauthAccessToken: string; // Identity に検証してもらう
}) {
try {
const res = await agentcore.send(
new InvokeAgentRuntimeCommand({
agentRuntimeId: process.env.AGENTCORE_RUNTIME_ID!,
// Identity の claim はトークンから自動で抽出される
identityContext: {
oidcToken: input.oauthAccessToken,
},
// Memory はこの actor_id をキーに長期記憶を引き当てる
sessionContext: {
actorId: input.actorId,
tenantId: input.tenantId,
sessionId: input.sessionId,
},
inputText: input.userQuestion,
enableTrace: true, // Observability にもトレースが流れる
}),
);
let fullText = "";
for await (const event of res.completion ?? []) {
if (event.chunk?.bytes) {
fullText += new TextDecoder().decode(event.chunk.bytes);
}
if (event.trace) {
// OTEL に流れていくので、ここではログだけ
console.error("[trace]", JSON.stringify(event.trace).slice(0, 300));
}
}
return fullText;
} catch (err: any) {
// ch09 と同じく throttling / timeout は個別ハンドル
if (err.name === "ThrottlingException") {
throw new Error("一時的に混雑しています。少し時間を置いて再度お試しください。");
}
if (err.name === "ModelTimeoutException") {
throw new Error("応答時間が長すぎました。質問を短くしてください。");
}
throw err;
}
}ここで意識してほしいのは、ビジネスロジック(Action Groups や Knowledge Bases 設定)には一切手を入れていないことだ。ch09 で作った helpdesk-ai は AgentCore に乗せ替えてもそのまま動く。差分はインフラ層だけ ── これが「下にインフラを敷く」の意味だ。
本番運用で効くベストプラクティス 3 つ
ここまでで helpdesk-ai は Production 級のインフラに乗った。仕上げに、AgentCore を本番運用するうえで押さえておきたいベストプラクティスを 3 つだけ紹介する6。
ベスプラ 1 : タイムアウトは「本番 / 開発」で値を変える
Runtime の idleTimeoutSeconds は 本番 idle 10–15 分、開発・デモ idle 2–5 分 が AWS の推奨だ。
- 本番:別件に気を取られて戻ってきても文脈を保ったまま会話再開できる。10–15 分が「席を外して戻れる」現実的な閾値
- 開発・デモ:忘れて放置したセッションが課金されないよう短めに切る
maxExecutionSeconds は最大 8 時間まで設定可能だが、対話型ユースケースで 8 時間は不要 ── これは長時間バッチ処理用の値だ。
ベスプラ 2 : ツール名フォーマットを守る
前述のとおり、ツール名は httpVerb__actionGroupName__apiName で統一する。
// ❌ 悪い例:エージェントが「どのツールか」を判断しにくい
{ name: "getBalance" }
{ name: "submit" }
{ name: "check" }
// ✅ 良い例:HTTP メソッド・ドメイン・操作が一目で読める
{ name: "get__hr__leave_balance" }
{ name: "post__hr__leave_request" }
{ name: "get__expense__category_list" }ツール数が増えてきたとき(10 個・20 個と並んだとき)、命名の一貫性は エージェントのツール選択精度に直接効く。最初の 1 つを定義するときから守っておくと、後の苦労が減る。
ベスプラ 3 : Guardian Agent パターンでドリフトを検知する
Fujitsu のサプライチェーンエージェントで使われている運用パターン7。メインのエージェントとは別に「ガーディアン」役を並走させ、メインの出力を継続的に監視する。
graph LR
User[ユーザー] --> Main[メインエージェント<br/>helpdesk-ai]
Main --> Tools[Gateway / KB / API]
Main --> Reply[応答]
Reply --> Guardian[Guardian Agent<br/>別 Runtime インスタンス]
Guardian -->|ドリフト検知| Alert[アラート / 介入]
Guardian -.->|学習データ| EvalDB[評価ログ]Guardian Agent は 社内ポリシー違反の回答・回答品質の時系列劣化・ツール呼び出しシーケンスの不自然な長さ(無限ループの兆候)を監視する。helpdesk-ai でも本番投入の少し前で 1 つ並走させ、評価ログを Part 3 の評価章(ch12)のデータソースにする。AgentCore Policy(2025-12 Preview)と組み合わせれば「自然言語ポリシー → Cedar 変換 → ツール呼び出しのプリフライト検査」まで自動化できる領域だ。
Bedrock Agents と AgentCore の使い分け
「Bedrock Agents を全部 AgentCore に置き換えるべきか?」という質問を受けることがある。答えは 「Production 要件が明確になってから」。
quadrantChart
title Bedrock Agents vs AgentCore の判断軸
x-axis "拡張性低い" --> "拡張性高い"
y-axis "本番要件少ない" --> "本番要件多い"
quadrant-1 "AgentCore"
quadrant-2 "AgentCore(要件絞り込み)"
quadrant-3 "Bedrock Agents"
quadrant-4 "Bedrock Agents → AgentCore 移行を検討"
"PoC / 社内デモ": [0.2, 0.2]
"中小規模本番(単一テナント)": [0.5, 0.5]
"マルチテナント SaaS": [0.8, 0.85]
"金融・規制業界": [0.85, 0.9]
"長時間バッチエージェント": [0.7, 0.7]| 状況 | 推奨 |
|---|---|
| すぐ動かしたい・フルマネージドが嬉しい | Bedrock Agents |
| 本番要件が明確(セッション分離・長期記憶・OAuth 連携・観測) | AgentCore |
| マルチテナント SaaS(テナントごとに違う構成) | AgentCore(Identity + Runtime のセッション分離が必須) |
| 任意フレームワーク(LangGraph / CrewAI / 自作) | AgentCore |
| 長時間(30 分超)の自動化タスク | AgentCore(Runtime の 8 時間実行) |
| MCP エコシステムに乗りたい | AgentCore(Gateway が REST API を MCP 化) |
実務的には「Bedrock Agents で PoC を通し、本番要件が見えた段階で AgentCore に乗せる」二段階アプローチが現実的だ。最初から AgentCore のフルセットを組むのは、要件が見えていないとオーバーキルになる。
helpdesk-ai は機能的にここまで来た
ch06 で Converse の 10 行から始めた helpdesk-ai は、Streaming と Tool Use、Knowledge Bases による RAG、Bedrock Agents の多段ステップ実行を経て、本章で Production 級のインフラに乗った。機能的にはほぼ完成だ。
残るのは「動く」を「安心して本番に置ける」に変えるための仕上げ ── Guardrails でブロックし、評価で測り、観測で気づき、セキュリティで防ぎ、コスト設計で避ける。これらが Part 3「Production Ready に仕上げる」の中身で、helpdesk-ai に本番要件を 1 つずつ重ねていくスパイラル構成になる。
本章で導入した AgentCore は、Part 3 と密接に結びついている。
- AgentCore Observability の OTEL Gen-AI セマンティクスは ch13「観測を設計する」で Langfuse / Datadog 連携まで掘り下げる
- AgentCore Evaluations(2025-12 Preview)の LLM-as-a-Judge は ch12「Day 1 から評価を組み込む」で実コードと共に扱う
- Toyota Motor North America の v1 RAG → v2 AgentCore 移行 と 住信 SBI ネット銀行の NEOBANK ai は ch16 の事例章で取り上げる
ch11 ではまず、最も「動かす前に決めておくべき」もの ── Guardrails から入る。「動いてから安全性を後付け」がなぜ失敗し、Detect モードでの段階導入がなぜ Production の標準解になるかを、helpdesk-ai に組み込みながら見ていこう。
章末まとめ
- AgentCore は Bedrock Agents の上位互換ではなく、別レイヤーの Production 向け共通インフラ。Bedrock Agents・Strands Agents SDK・LangGraph などをすべて上に乗せられる
- 9 コンポーネント(Runtime / Memory / Identity / Gateway / Browser / Code Interpreter / Observability / Policy / Evaluations)が、マネージドな ReAct には足りない本番要件を 1 つずつ埋める
- helpdesk-ai の移行は ロジック据え置きで周りをインフラで包む 形。Identity で Slack OAuth を引き継ぎ、Gateway で人事 API を MCP 化し、Memory で個人別の長期記憶を持たせ、Runtime に Bedrock Agents をそのまま乗せた
- 本番運用のベスプラ:タイムアウトは本番 10–15 分 / 開発 2–5 分、ツール名は
httpVerb__actionGroupName__apiName、Guardian Agent パターンでドリフト検知- 「すぐ動かすなら Bedrock Agents、Production 要件が見えたら AgentCore」の二段階アプローチが現実的
- Part 3 では Guardrails・評価・観測・セキュリティ・コストを helpdesk-ai に順次重ねていく。次章は Guardrails から
Footnotes
-
Amazon Bedrock AgentCore is now generally available(2025-10)。Preview は 2025-07 の AWS Summit NYC で発表された。 ↩
-
Amazon Bedrock AgentCore announces Policy and Evaluations in preview(2025-12 re:Invent)。本章執筆時点では Preview のため、本番採用時は最新リリースノート参照。 ↩ ↩2
-
AI agents in enterprises: Best practices with Amazon Bedrock AgentCore ↩
-
Amazon Bedrock AgentCore Memory: Building context-aware agents ↩
-
Episodic memory は 2025-12 で追加された比較的新しいストラテジ。helpdesk-ai では当初は Summary + Semantic から始め、運用しながら Episodic の追加を検討する流れが現実的。 ↩
-
AI agents in enterprises: Best practices with Amazon Bedrock AgentCore、および Classmethod: Bedrock AgentCore 本番導入への道 より整理。 ↩
-
Fujitsu のサプライチェーンエージェント事例で紹介された設計パターン(re:Invent 2025 セッション)。 ↩