プロローグ:Bedrock で Production Ready な AI を作る地図を手にする
「AI 機能を入れたい」と言われた、ある朝
上司に呼ばれて、こう言われた、と仮定してほしい。
「うちのプロダクトに AI 機能を入れたい。要件はまだ詰めていない。何でもいいから、まず動くものを見せてくれ。インフラは AWS だから、たぶん Bedrock でいけるよね」
たぶん、いける。あなたは AWS の中級者で、IAM も VPC も Lambda も、まあ仕事で読み書きできる。OpenAI の API は遊びで叩いたことがある。RAG というキーワードも知っている。
その日の昼休みに、Bedrock のドキュメントを開く。1 時間後、ブラウザのタブは 17 個になっている。Foundation Models、Knowledge Bases、Bedrock Agents、AgentCore、Guardrails、Model Evaluation、Prompt Management、Application Inference Profiles、Cross-Region Inference、Provisioned Throughput、Bedrock IDE …。
便利そうだ。だが、何から手を付ければいいのかが、よくわからない。
- どのモデルを選べばいいのか
- Knowledge Bases と Bedrock Agents と AgentCore、どれを使うのが正解なのか
- Guardrails はいつ入れるべきか
- コストは「PoC のまま本番に出す」とどれくらい膨らむのか
- OpenAI 直叩きと比べて、何が嬉しくて、何が困るのか
このシリーズは、その「何をどの順で考えればいいか」を、設計から運用まで貫通させて答えるためのものだ。
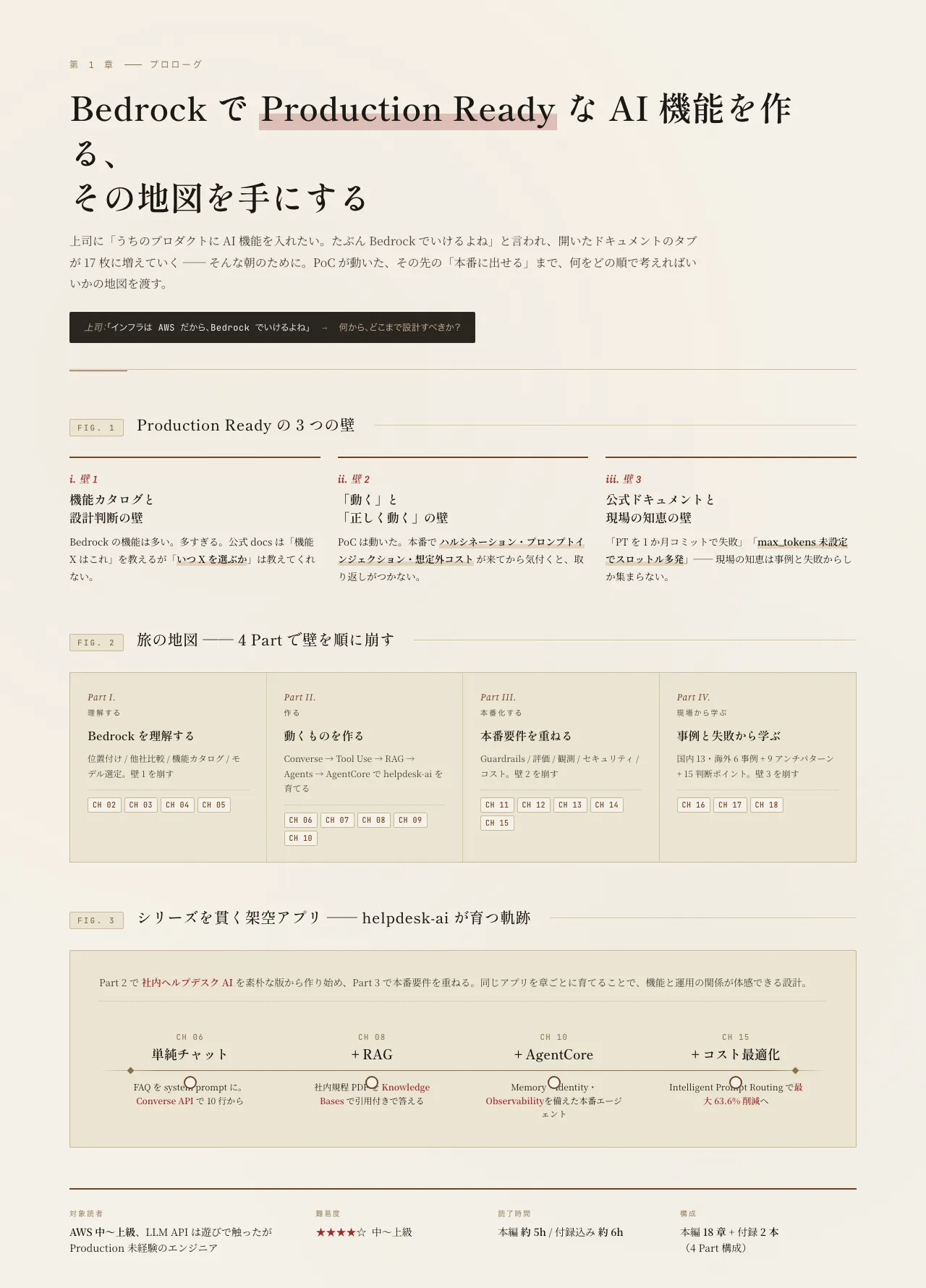
Production Ready の 3 つの壁
「動く」と「本番に置ける」の間には、3 つの壁がある。
壁 1:機能カタログと設計判断の壁
Bedrock の機能は多い。多すぎる。公式ドキュメントは「機能 X はこういうもの」を説明するが、「いつ X を選ぶべきか」は教えてくれない。
InvokeModel で済む話なのか、Knowledge Bases を使うべきか、Bedrock Agents が必要か、AgentCore に行くべきか。これは「機能の理解」ではなく「設計判断」の問題だ。
壁 2:「動く」と「正しく動く」の壁
PoC は動いた。デモも通った。本番に出したら、ある日突然「ハルシネーション」「プロンプトインジェクション」「想定外のコスト」が来る。
これは Bedrock 特有の問題ではなく、LLM をプロダクションで運用するときに必ず通る道だ。Bedrock には Guardrails・Model Evaluation・LLM-as-a-Judge という道具があるが、これを「いつ・どう・どこまで」入れるかが設計の核心になる。
壁 3:公式ドキュメントと現場の知恵の壁
公式ドキュメントは正しい。だが、現場で実際に起きていることは別の場所に書いてある。
「Provisioned Throughput を 1 か月コミットで買って失敗した」「max_tokens を未設定にしてスロットルが多発した」「Mask モードで PII を消したつもりが、Model Invocation Logs に原文が残っていた」── これらは公式 docs には書かれていない(または、書かれているが目立たない)。現場の知恵は、事例と失敗から集めるしかない。
このシリーズが解こうとしている問題
上の 3 つの壁を、Bedrock の機能と現場の事例を使って、順番に壊していく。具体的には、4 つの Part に分けて進める。
- Part 1(5 章):Bedrock を理解する ── 位置付け、他社比較、機能カタログ、モデル選定。壁 1 を壊す
- Part 2(5 章):動くものを作る ── Converse API → Streaming → Tool Use → RAG → Agents → AgentCore。素朴な実装から始めて、段階的に増築する
- Part 3(5 章):Production Ready に仕上げる ── Guardrails、評価、観測、セキュリティ、コスト。壁 2 を壊す
- Part 4(3 章):現場から学ぶ ── 国内・海外の事例、9 つのアンチパターン、エピローグ。壁 3 を壊す
シリーズを貫通する 架空のサンプルアプリ を 1 つ用意した。「helpdesk-ai」── 社内ヘルプデスクの問い合わせに答える AI アシスタント、というよくある題材だ。Part 2 でこれを段階的に作り、Part 3 で本番要件を順次重ねていく。
このシリーズが提供しないこと
公平のため、提供しないことも先に言っておく。
- AWS の入門ではない。IAM・VPC・Lambda・CloudWatch を仕事で読み書きできる前提
- LLM の入門ではない。OpenAI 等で「動くものは作ったことがある」前提
- 特定モデルの深堀りではない。「Claude Sonnet のプロンプトテクニック完全版」のような専門書とは別物
- 完全網羅型のリファレンスではない。Bedrock の全機能を等しく扱うのではなく、「Production Ready に至る道筋」に必要なものを選択している
なぜ「設計→実装→本番化→事例」の順なのか
ネットワーク・コンピューティングと違って、LLM の本番運用は 「動かしてから直す」アプローチが極めて不利な領域だ。理由は 3 つ。
- コストが想定の 10 倍になることが日常的に起きる(事例:とあるサードパーティ調査では PT 無駄買いで月 30〜50% 余計に払うケースが多い)
- ハルシネーションは事後で気付くことが多い。気付いた頃にはユーザーの信頼を失っている
- 観測を後付けすると、何が問題か再現すらできない
だから、Day 1 から評価・観測・ガードレールを設計に組み込む。それを Production Ready と呼ぶ。
このシリーズは、PoC で満足しないで本番に出したい人のためのものだ。
旅の地図
| 部 | 章 | 何を扱うか |
|---|---|---|
| Part 1 理解する | 第 2 〜 5 章 | Bedrock の位置付け、他社比較、機能カタログ、モデル選定 |
| Part 2 作る | 第 6 〜 10 章 | Converse → Tool Use → RAG → Agents → AgentCore(helpdesk-ai を育てる) |
| Part 3 本番化する | 第 11 〜 15 章 | Guardrails、評価、観測、セキュリティ、コスト |
| Part 4 現場から学ぶ | 第 16 〜 18 章 | 事例、アンチパターン、エピローグ |
| 付録 | A / B | マルチリージョン設計 / コスト見積もりワークシート |
それでは、第 2 章で「Bedrock の位置付け」から始めよう。AWS の 3 階層 Generative AI Stack の中で、Bedrock がどこに置かれているのか ── ここを押さえることが、シリーズ全体の地図を読むための最初の鍵になる。
章末まとめ
- Production Ready には 3 つの壁がある:機能カタログと設計判断の壁・「動く」と「正しく動く」の壁・公式と現場の壁
- 本シリーズは「理解 → 作る → 本番化 → 現場から学ぶ」の 4 部構成
- シリーズを貫く架空アプリ「helpdesk-ai」を Part 2 で段階的に作り、Part 3 で本番要件を重ねる
- Day 1 から評価・観測・ガードレールを設計に組み込むのが本シリーズの中心思想
- 次章では Bedrock の位置付けを AWS Generative AI Stack の中で整理する