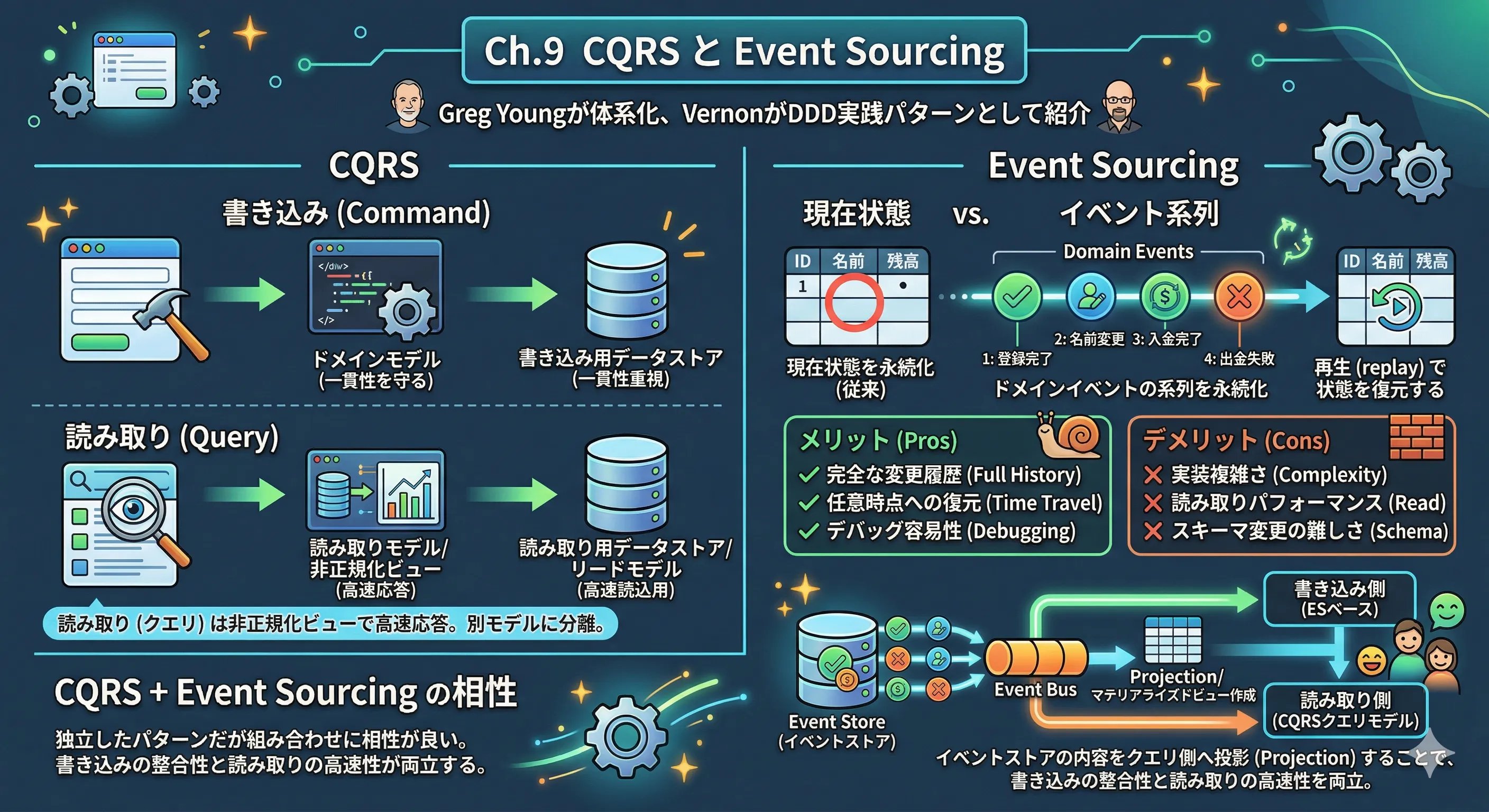
CQRSとは何か
Evans の「ドメイン駆動設計」(2003年)には、コマンドクエリ責務分離(Command Query Responsibility Segregation、以下CQRS)についての記述はない。Evans がその著作で集中して扱ったのは、ドメインモデルそのものの設計であり、そのモデルをどのようにアーキテクチャへ反映させるかという問いは次世代の課題として残された。
CQRSを体系化したのは Greg Young である。Young はバートランド・メイヤーが提唱したコマンドクエリ分離(Command Query Separation、以下CQS)の原則 ── メソッドは状態を変更するコマンドか状態を返すクエリかのどちらかであり、両方を兼ねてはならない ── をアーキテクチャレベルに発展させた。Vernon はこのアイデアを「実装するドメイン駆動設計」(2013年)の中で DDD の実践パターンとして詳細に取り上げ、ドメインモデルと組み合わせる具体的な手法を示した。
CQRS の定義はシンプルだ。状態を変更するコマンド(Command)と、状態を読み取るクエリ(Query)を、明確に異なるモデルとして分離する設計パターンである。同一のオブジェクトがコマンドとクエリの両方を担う通常の設計に対し、CQRS はこれを意図的に切り離す。
なぜ読み書きを分けるのか
多くのシステムにおいて、書き込み処理と読み取り処理は異なる性質を持つ。
書き込み側は、ドメインの一貫性保護を最優先にする必要がある。集約はビジネスルールを守るための境界として機能し、トランザクションの整合性を担保する。採用管理システムで言えば、「選考プロセスを次のステージへ進める」という操作は、現在のステージが何であるか、前提条件を満たしているかを検証したうえで状態を更新する。この処理には複雑なドメインロジックが伴う。
読み取り側の要求は異なる。「現在進行中の選考一覧をダッシュボードに表示する」というクエリは、複数の候補者・求人・ステージにまたがる非正規化されたデータを、表示のニーズに合わせて高速に返す必要がある。この要件に対してドメインモデルの集約を経由することは、多くの場合で過剰だ。
単一のモデルで両方の要求を満たそうとすると、次のトレードオフが生じる。ドメインロジックの一貫性を守るために正規化されたモデルを使うと、複雑な読み取りクエリが重くなる。読み取りのために最適化された非正規化ビューを使うと、書き込み時の一貫性保護が難しくなる。
CQRS はこのトレードオフを「分離」によって解消する。書き込みモデルはドメインの一貫性保護に集中し、読み取りモデルは表示のニーズに最適化する。それぞれを独立して発展させられる。
TypeScriptでCQRSを実装する
採用管理システムの選考管理コンテキストを例に実装を示す。
// コマンド: 選考プロセスを次のステージへ進める
class AdvanceScreeningCommand {
constructor(
readonly screeningProcessId: string,
readonly advancedBy: string,
) {}
}
// コマンドハンドラー: ドメインモデルを通じて状態を変更する
class AdvanceScreeningHandler {
constructor(private readonly repo: ScreeningProcessRepository) {}
async handle(cmd: AdvanceScreeningCommand): Promise<void> {
const process = await this.repo.findById(cmd.screeningProcessId)
// ドメインロジックはエンティティ内に閉じている
process.advanceStage()
await this.repo.save(process)
}
}
// クエリ結果の型: 表示に最適化された読み取り専用データ構造
interface ScreeningDashboardDTO {
screeningProcessId: string
candidateName: string
jobTitle: string
currentStage: string
lastUpdatedAt: Date
}
// クエリ: 読み取り専用の最適化されたビューを返す
class ScreeningDashboardQuery {
constructor(private readonly readDb: ReadOnlyDatabase) {}
async execute(recruiterId: string): Promise<ScreeningDashboardDTO[]> {
// 読み取り専用DBやキャッシュから非正規化済みデータを直接取得
// 集約を経由しないため、ドメインオブジェクトの生成コストが発生しない
return this.readDb.query(
`SELECT ... FROM screening_views WHERE recruiter_id = ?`,
[recruiterId],
)
}
}コマンドハンドラーとクエリは、それぞれが異なるデータソースを持つことができる。書き込み側はドメインモデルとリポジトリを通じて正規化された永続化ストアに書き込み、読み取り側は非正規化された読み取り専用ビューから直接データを取得する。2つのモデルの同期は非同期のイベントによって行うことが多い。
Event Sourcingとは何か
通常の永続化戦略では、集約の現在の状態をデータベースの1行(あるいは1ドキュメント)として保存する。ScreeningProcess の現在のステージが「二次面接」であれば、そのレコードには stage = 'second_interview' が記録される。過去の状態 ── 「書類選考だったのはいつか」「一次面接を通過したのはいつか」── は、別途履歴テーブルを設けない限り失われる。
イベントソーシング(Event Sourcing)は異なるアプローチをとる。集約の現在の状態をそのまま保存するのではなく、その集約に起きたドメインイベントの系列を保存する。現在の状態はそのイベント列を再生(replay)することで導出する。
Vernon は「実装するドメイン駆動設計」の中で、ドメインイベントをどう永続化するかという問いへの解として Event Sourcing を提示している。ドメインイベントが設計の中心に据えられたとき、そのイベントをそのまま永続化することには一貫性がある。イベントは不変であり、起きた事実の記録として扱われる。
採用管理システムの選考プロセスを例にとると、イベントストアには次のような記録が積み上がる。
screening_process_id: "sp-001"
────────────────────────────────────────────────────────────
seq | event_type | occurred_at
────────────────────────────────────────────────────────────
1 | DocumentScreeningStarted | 2026-01-10 09:00
2 | DocumentScreeningCompleted | 2026-01-12 14:30
3 | FirstInterviewScheduled | 2026-01-13 10:00
4 | FirstInterviewCompleted | 2026-01-20 16:00
5 | SecondInterviewScheduled | 2026-01-21 11:00
────────────────────────────────────────────────────────────このイベント列を最初から再生すると、現在の状態(「二次面接が設定済み」)が導出される。新しいイベントが発生するたびに、列の末尾にレコードが追加されるだけであり、既存のレコードは変更されない。
TypeScript での実装例を示す。
// ドメインイベントの基底型
interface DomainEvent {
readonly eventType: string
readonly occurredAt: Date
readonly aggregateId: string
}
// 具体的なドメインイベント
class FirstInterviewCompleted implements DomainEvent {
readonly eventType = 'FirstInterviewCompleted'
constructor(
readonly aggregateId: string,
readonly occurredAt: Date,
readonly interviewerId: string,
) {}
}
// イベントソーシングを使う集約の骨格
class ScreeningProcess {
private stage: ScreeningStage
private uncommittedEvents: DomainEvent[] = []
// プライベートコンストラクタ: イベント再生からのみ生成
private constructor() {}
// イベントストアから復元する
static reconstitute(events: DomainEvent[]): ScreeningProcess {
const process = new ScreeningProcess()
for (const event of events) {
process.apply(event)
}
return process
}
// コマンドの実行: 検証後にイベントを発行
completeFirstInterview(interviewerId: string): void {
if (!this.stage.isFirstInterview()) {
throw new Error('First interview has not started')
}
const event = new FirstInterviewCompleted(
this.aggregateId,
new Date(),
interviewerId,
)
this.apply(event)
this.uncommittedEvents.push(event)
}
// イベントを適用して状態を更新
private apply(event: DomainEvent): void {
if (event.eventType === 'FirstInterviewCompleted') {
this.stage = ScreeningStage.secondInterview()
}
// 他のイベントタイプも同様に処理
}
// リポジトリが未コミットのイベントを取得して永続化する
getUncommittedEvents(): DomainEvent[] {
return [...this.uncommittedEvents]
}
}集約の apply メソッドがイベントを受け取り状態を更新する点が Event Sourcing の核心だ。再生時もコマンド実行時も、状態の更新は同一の apply を通じて行われる。
Event Sourcingのメリットとデメリット
メリット
完全な変更履歴の保持: 通常の設計では上書きされて消えてしまう過去の状態が、イベントとして永続的に記録される。「この候補者がなぜ今このステージにいるのか」をイベント列から完全にトレースできる。
任意時点への状態復元: イベントを特定の時点まで再生することで、過去の任意の時点における状態を再現できる。バグ調査や監査ログの用途に直接応える。
デバッグのしやすさ: 本番環境で発生した問題を再現するために、イベント列をそのままテスト環境で再生できる。状態遷移のどの段階で問題が起きたかを特定しやすい。
ドメインイベントの一級市民化: イベントが永続化の単位になることで、システム内のドメインイベントとストレージのモデルが一致する。イベントを他のコンテキストへ配信する非同期処理とも親和性が高い。
デメリット
実装の複雑さ: 通常の CRUD ベースの永続化より実装量が増える。イベントストアの設計、集約の復元ロジック、スキーマのバージョニングなど、考慮すべき要素が多い。
読み取りのパフォーマンス: イベント列が長くなるほど、集約を復元するための再生コストが増大する。これへの対処がスナップショット(snapshot)だ。定期的に集約の現在の状態をスナップショットとして保存し、次回の復元時にはスナップショット以降のイベントのみを再生する。
スキーマの変化への対応: イベントは不変の記録であるため、イベントの構造を変更することが難しい。数年後に過去のイベントを再生する際、古いフォーマットとの互換性をどう保つかという問題が生じる。
適用範囲の注意点
Vernon 自身も、Event Sourcing をすべての集約に適用すべきではないと明言している。変更履歴の追跡が業務上意味を持つ集約 ── 採用管理システムで言えば選考プロセス ── には適するが、シンプルな参照データや変更頻度の低いマスタデータには過剰な設計になる。「技術的に面白い」という理由だけで採用すると、複雑さだけが積み上がる。
CQRSとEvent Sourcingの関係
CQRS と Event Sourcing はセットで語られることが多いが、それぞれ独立したパターンである。CQRSなしに Event Sourcing を実装することも、Event Sourcingなしに CQRSを実装することも可能だ。
ただし、組み合わせたときの相性は良い。
Event Sourcing を採用すると、イベントストアが書き込みの記録になる。このイベントをリアルタイムに読み取り側へ投影(projection)することで、CQRS の読み取りモデルを最新の状態に保てる。書き込み側はイベントを追記するだけでよく、読み取り側はそのイベントを購読して自分に最適化されたビューを更新する。
採用管理システムでは、選考管理コンテキストが SecondInterviewScheduled イベントを発行すると、そのイベントがダッシュボード用の読み取りモデルに投影される。採用担当者が見るダッシュボードは、イベントの投影から生成された非正規化されたビューから直接データを取得する。書き込み側の整合性と読み取り側のパフォーマンスが、分離された設計によって両立する。
インフォグラフィック
graph LR
subgraph cmd["コマンド側(書き込み)"]
A["採用担当者"] -->|AdvanceScreeningCommand| B["コマンドハンドラー"]
B --> C["ScreeningProcess\n(集約)"]
C -->|イベント発行| D[("イベントストア\n─────────────\nDocumentScreeningStarted\nFirstInterviewScheduled\nFirstInterviewCompleted\nSecondInterviewScheduled\n...")]
end
subgraph query["クエリ側(読み取り)"]
E["ScreeningDashboardQuery"] --> F[("読み取りモデル\n─────────────\nscreening_views\n非正規化ビュー")]
F -->|ScreeningDashboardDTO| G["ダッシュボード画面"]
end
D -->|イベント投影\n(Projection)| F
style cmd fill:#f0f4ff,stroke:#99aadd
style query fill:#f0fff4,stroke:#99ddaa図の左側がコマンド側、右側がクエリ側である。コマンドハンドラーはドメインモデルを通じてイベントストアへ書き込む。イベントストアに積み上がったイベントは、非同期に読み取りモデルへ投影される。クエリは読み取りモデルから直接データを取得し、ドメインモデルを経由しない。2つの側が異なるストアを持つことで、それぞれを独立してスケールさせることもできる。